并行运行
当 TensorFlow 运行图时,它首先找出需要求值的节点列表,然后计算每个节点有多少依赖关系。 然后 TensorFlow 开始求值具有零依赖关系的节点(即源节点)。 如果这些节点被放置在不同的设备上,它们显然会被并行求值。 如果它们放在同一个设备上,它们将在不同的线程中进行求值,因此它们也可以并行运行(在单独的 GPU 线程或 CPU 内核中)。
TensorFlow 管理每个设备上的线程池以并行化操作(参见图 12-5)。 这些被称为 inter-op 线程池。 有些操作具有多线程内核:它们可以使用其他线程池(每个设备一个)称为 intra-op 线程池(下面写成内部线程池)。
<p style="text-align:center">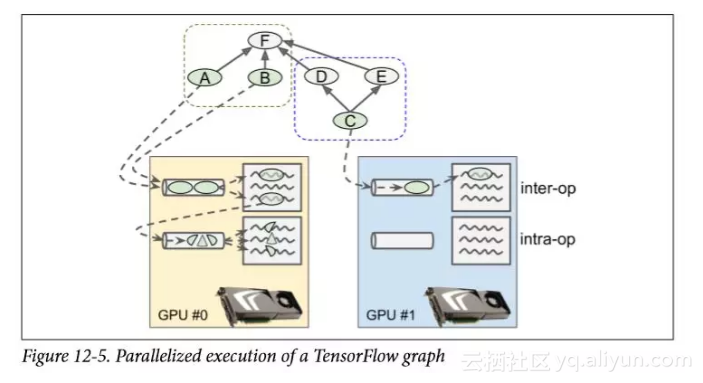
</p>
例如,在图 12-5 中,操作A,B和C是源操作,因此可以立即进行求值。 操作A和B放置在 GPU#0 上,因此它们被发送到该设备的内部线程池,并立即进行并行求值。 操作A正好有一个多线程内核; 它的计算被分成三部分,这些部分由内部线程池并行执行。 操作C转到 GPU#1 的内部线程池。
一旦操作C完成,操作D和E的依赖性计数器将递减并且都将达到 0,因此这两个操作将被发送到操作内线程池以执行。
您可以通过设置inter_op_parallelism_threads选项来控制内部线程池的线程数。 请注意,您开始的第一个会话将创建内部线程池。 除非您将use_per_session_threads选项设置为True,否则所有其他会话都将重用它们。 您可以通过设置intra_op_parallelism_threads选项来控制每个内部线程池的线程数。
控制依赖关系
在某些情况下,即使所有依赖的操作都已执行,推迟对操作的求值可能也是明智之举。例如,如果它使用大量内存,但在图形中只需要更多内存,则最好在最后一刻对其进行求值,以避免不必要地占用其他操作可能需要的 RAM。 另一个例子是依赖位于设备外部的数据的一组操作。 如果它们全部同时运行,它们可能会使设备的通信带宽达到饱和,并最终导致所有等待 I/O。 其他需要传递数据的操作也将被阻止。 顺序执行这些通信繁重的操作将是比较好的,这样允许设备并行执行其他操作。
推迟对某些节点的求值,一个简单的解决方案是添加控制依赖关系。 例如,下面的代码告诉 TensorFlow 仅在求值完a和b之后才求值x和y:
```js
a = tf.constant(1.0)
b = a + 2.0
with tf.control_dependencies([a, b]):
x = tf.constant(3.0)
y = tf.constant(4.0)
z = x + y
```
显然,由于z依赖于x和y,所以求值z也意味着等待a和b进行求值,即使它并未显式存在于control_dependencies()块中。 此外,由于b依赖于a,所以我们可以通过在[b]而不是[a,b]上创建控制依赖关系来简化前面的代码,但在某些情况下,“显式比隐式更好”。
很好!现在你知道了:
如何以任何您喜欢的方式在多个设备上进行操作
这些操作如何并行执行
如何创建控制依赖性来优化并行执行
是时候将计算分布在多个服务器上了!
多个服务器的多个设备
要跨多台服务器运行图形,首先需要定义一个集群。 一个集群由一个或多个 TensorFlow 服务器组成,称为任务,通常分布在多台机器上(见图 12-6)。 每项任务都属于一项作业。 作业只是一组通常具有共同作用的任务,例如跟踪模型参数(例如,参数服务器通常命名为"ps",parameter server)或执行计算(这样的作业通常被命名为"worker")。
<p style="text-align:center">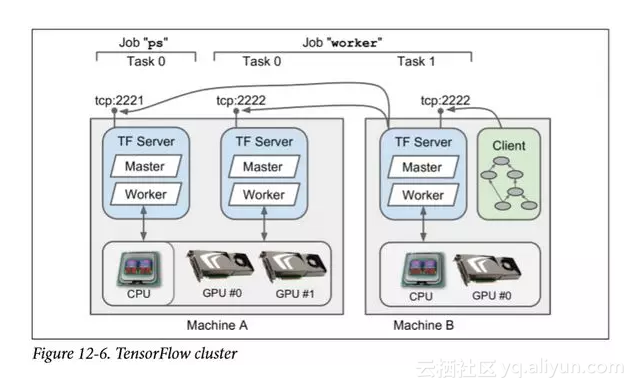</p>
以下集群规范定义了两个作业"ps"和"worker",分别包含一个任务和两个任务。 在这个例子中,机器A托管着两个 TensorFlow 服务器(即任务),监听不同的端口:一个是"ps"作业的一部分,另一个是"worker"作业的一部分。 机器B仅托管一台 TensorFlow 服务器,这是"worker"作业的一部分。
```js
cluster_spec = tf.train.ClusterSpec({
"ps": [
"machine-a.example.com:2221", # /job:ps/task:0
],
"worker": [
"machine-a.example.com:2222", # /job:worker/task:0
"machine-b.example.com:2222", # /job:worker/task:1
]})
```
要启动 TensorFlow 服务器,您必须创建一个服务器对象,并向其传递集群规范(以便它可以与其他服务器通信)以及它自己的作业名称和任务编号。 例如,要启动第一个辅助任务,您需要在机器 A 上运行以下代码:
```js
server = tf.train.Server(cluster_spec, job_name="worker", task_index=0)
```
每台机器只运行一个任务通常比较简单,但前面的例子表明 TensorFlow 允许您在同一台机器上运行多个任务(如果需要的话)。 如果您在一台机器上安装了多台服务器,则需要确保它们不会全部尝试抓取每个 GPU 的所有 RAM,如前所述。 例如,在图12-6中,"ps"任务没有看到 GPU 设备,想必其进程是使用CUDA_VISIBLE_DEVICES =""启动的。 请注意,CPU由位于同一台计算机上的所有任务共享。
如果您希望进程除了运行 TensorFlow 服务器之外什么都不做,您可以通过告诉它等待服务器使用join()方法来完成,从而阻塞主线程(否则服务器将在您的主线程退出)。 由于目前没有办法阻止服务器,这实际上会永远阻止:
```js
server.join() # blocks until the server stops (i.e., never)
```
开始一个会话
一旦所有任务启动并运行(但还什么都没做),您可以从位于任何机器上的任何进程(甚至是运行中的进程)中的客户机上的任何服务器上打开会话,并使用该会话像普通的本地会议一样。比如:
```js
a = tf.constant(1.0)
b = a + 2
c = a * 3
with tf.Session("grpc://machine-b.example.com:2222") as sess:
print(c.eval()) # 9.0
```
这个客户端代码首先创建一个简单的图形,然后在位于机器 B(我们称之为主机)上的 TensorFlow 服务器上打开一个会话,并指示它求值c。 主设备首先将操作放在适当的设备上。 在这个例子中,因为我们没有在任何设备上进行任何操作,所以主设备只将它们全部放在它自己的默认设备上 - 在这种情况下是机器 B 的 GPU 设备。 然后它只是按照客户的指示求值c,并返回结果。
主机和辅助服务
客户端使用 gRPC 协议(Google Remote Procedure Call)与服务器进行通信。 这是一个高效的开源框架,可以调用远程函数,并通过各种平台和语言获取它们的输出。它基于 HTTP2,打开一个连接并在整个会话期间保持打开状态,一旦建立连接就可以进行高效的双向通信。
数据以协议缓冲区的形式传输,这是另一种开源 Google 技术。 这是一种轻量级的二进制数据交换格式。
TensorFlow 集群中的所有服务器都可能与集群中的任何其他服务器通信,因此请确保在防火墙上打开适当的端口。
每台 TensorFlow 服务器都提供两种服务:主服务和辅助服务。 主服务允许客户打开会话并使用它们来运行图形。 它协调跨任务的计算,依靠辅助服务实际执行其他任务的计算并获得结果。
固定任务的操作
通过指定作业名称,任务索引,设备类型和设备索引,可以使用设备块来锁定由任何任务管理的任何设备上的操作。 例如,以下代码将a固定在"ps"作业(即机器 A 上的 CPU)中第一个任务的 CPU,并将b固定在"worker"作业的第一个任务管理的第二个 GPU (这是 A 机上的 GPU#1)。 最后,c没有固定在任何设备上,所以主设备将它放在它自己的默认设备上(机器 B 的 GPU#0 设备)。
```js
with tf.device("/job:ps/task:0/cpu:0")
a = tf.constant(1.0)
with tf.device("/job:worker/task:0/gpu:1")
b = a + 2
c = a + b
```
如前所述,如果您省略设备类型和索引,则 TensorFlow 将默认为该任务的默认设备; 例如,将操作固定到"/job:ps/task:0"会将其放置在"ps"作业(机器 A 的 CPU)的第一个任务的默认设备上。 如果您还省略了任务索引(例如,"/job:ps"),则 TensorFlow 默认为"/task:0"。如果省略作业名称和任务索引,则 TensorFlow 默认为会话的主任务。
跨多个参数服务器的分片变量
正如我们很快会看到的那样,在分布式设置上训练神经网络时,常见模式是将模型参数存储在一组参数服务器上(即"ps"作业中的任务),而其他任务则集中在计算上(即 ,"worker"工作中的任务)。 对于具有数百万参数的大型模型,在多个参数服务器上分割这些参数非常有用,可以降低饱和单个参数服务器网卡的风险。 如果您要将每个变量手动固定到不同的参数服务器,那将非常繁琐。 幸运的是,TensorFlow 提供了replica_device_setter()函数,它以循环方式在所有"ps"任务中分配变量。 例如,以下代码将五个变量引入两个参数服务器:
```js
with tf.device(tf.train.replica_device_setter(ps_tasks=2):
v1 = tf.Variable(1.0) # pinned to /job:ps/task:0
v2 = tf.Variable(2.0) # pinned to /job:ps/task:1
v3 = tf.Variable(3.0) # pinned to /job:ps/task:0
v4 = tf.Variable(4.0) # pinned to /job:ps/task:1
v5 = tf.Variable(5.0) # pinned to /job:ps/task:0
```
您不必传递ps_tasks的数量,您可以传递集群spec = cluster_spec,TensorFlow 将简单计算"ps"作业中的任务数。
如果您在块中创建其他操作,则不仅仅是变量,TensorFlow 会自动将它们连接到"/job:worker",默认为第一个由"worker"作业中第一个任务管理的设备。 您可以通过设置worker_device参数将它们固定到其他设备,但更好的方法是使用嵌入式设备块。 内部设备块可以覆盖在外部块中定义的作业,任务或设备。 例如:
```js
with tf.device(tf.train.replica_device_setter(ps_tasks=2)):
v1 = tf.Variable(1.0) # pinned to /job:ps/task:0 (+ defaults to /cpu:0)
v2 = tf.Variable(2.0) # pinned to /job:ps/task:1 (+ defaults to /cpu:0)
v3 = tf.Variable(3.0) # pinned to /job:ps/task:0 (+ defaults to /cpu:0)
[...]
s = v1 + v2 # pinned to /job:worker (+ defaults to task:0/gpu:0)
with tf.device("/gpu:1"):
p1 = 2 * s # pinned to /job:worker/gpu:1 (+ defaults to /task:0)
with tf.device("/task:1"):
p2 = 3 * s # pinned to /job:worker/task:1/gpu:1
```
这个例子假设参数服务器是纯 CPU 的,这通常是这种情况,因为它们只需要存储和传送参数,而不是执行密集计算。
原文发布时间为:2018-06-28
本文作者:ApacheCN【翻译】