一、问题描述
在一场面试中,面试官问到了React和Node路由之间的关系.
现在SPA(单页面应用)的使用越来越广。
Node(后台)和React(前端)都有自己的路由,当我页面访问一个URL的时候,其中的路由究竟是以哪个为准呢?
答案是Node路由优先级更高
所以会经常出现React设置了Router,但刷新访问的时候就出现了404.
因为当你刷新一个URL时,首先会在node中识别是否存在这个路由,因为我们并没有设置这个路由(仅仅在React中设置了而已),所以会出现Can't not GET /xxx
二、解决方法
可能想到既然是Node先处理url,那我保证Node和React的路由都一致不就行了!这样既不错报错也能执行React的路由了。
貌似确实行得通!但是这样不仅麻烦,而且官方不建议!
下面提供部分方法可以解决大部分简单的情况:
2.1 Node(express/koa)只渲染html
这个是我最经常使用的方式
```
var express = require('express');
var router = express.Router();
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index');
});
用webpack打包(也可以不打包)后,在根html模板里引入相关的js, 然后node用根路径`/`去匹配该html模板.这样无论如何node都不会报404了
<h4>2.2 在node返回404的时候,指向html</h4>
router.get('*',(ctx, next) => {
ctx.type = 'html';
ctx.body = fs.createReadStream('./index.html');
});
<h4>2.3 选择合适的路由方式</h4>
`hashRouter`: hash路由会挂在服务端所有路由到前端
`BrowserRouter`: history 模式(BrowserRouter:浏览器路由)改变 url 的方式会导致浏览器向服务器发送请求,如果匹配不到任何静态资源,则应该始终返回同一个 html 页面。
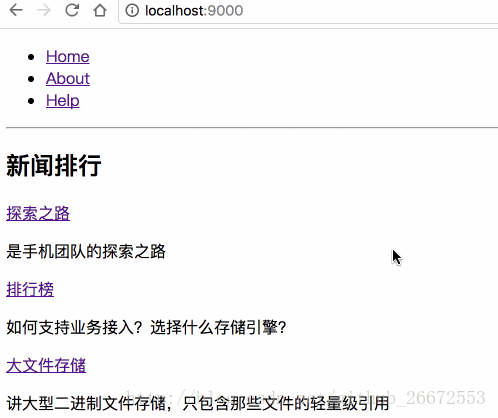
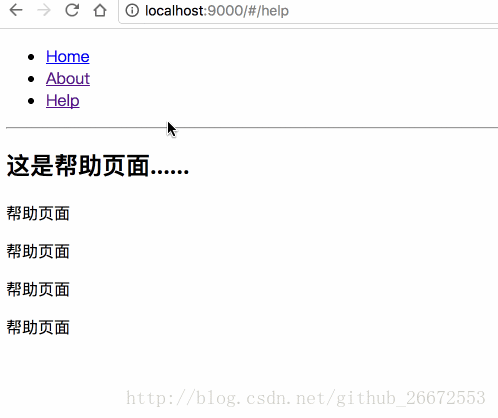
比如下面两个图的对比:
<b>histroy模式(BrowserRouter)</b>
<b>hash模式</b>
>图片来源于<a href="https://blog.csdn.net/github_26672553/article/details/76906488" target="_blank">《react.js的两种路由方式:HashRouter》</a>
可以看到hash路由解决了这个问题,但是hash路由多了一个丑丑的`/#/`
使用hashHistory时,因为有 # 的存在,浏览器不会发送request,react-router 自己根据 url 去 render 相应的模块。
<h3>三、后续</h3>
当然,路由的选择不仅仅局限于此,还包括是否需要按需加载、路由参数使用等等。
后面会解释一下为什么hash路由路径上会出现这么多的哈希值,并且出现的原因和作用是什么?
`react-route`底层的一些原理和详细的用法可以参考这篇文章:
<a href="https://www.cnblogs.com/wyaocn/p/5805777.html" target="_blank">《
深入理解 react-router 路由系统》</a>