代码补全快餐教程(1) - 30行代码见证奇迹
下面是我用30多行代码,包含了很多空行和注释的代码写成的代码补全模型。我们先看看效果吧。
补全效果案例
先来看个比较普通的(Python, Keras)
已知:
y_train = keras.utils.to_categorical(y_train, num_classes)\ny_test = keras.`
补全之后是这样的:y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
算法能够知道把括号中的y_train换成y_test
### 再看一个把我感动哭了的(Typescript, vscode)
输入如下:text = "let disposable_begin_buffer = vscode.commands.registerCommand('extension.littleemacs.beginningOfBuffer',nmove.beginningOfBuffer);nlet disposable_end_buffer = vscode.commands."
输出是这样的:let disposable_begin_buffer = vscode.commands.registerCommand('extension.littleemacs.beginningOfBuffer',move.beginningOfBuffer);
let disposable_end_buffer = vscode.commands.registerCommand('extension.littleemacs.endendOfBuffer',move.endendOfBuffer);
请注间这其中的难度,变量定义中用的是begin,而extension和move中用的都是beginning,算法能将其换成endend而保持OfBuffer不变。
### 函数的补全(Java)
输入如下:public class Issue {nprivate Long id;nprivate String filename;nprivate Long lineNum;nprivate String issueString;npublic Long getId() {
输出如下:public class Issue {
private Long id;
private String filename;
private Long lineNum;
private String issueString;
public Long getId() { return id; }
对于IntellJ IDEA来说这不算什么,但是对于完全不懂Java语言的文本模型,隔着几行其它变量能把return id给补全出来还是很了不起的
### 能看懂循环(Java, Android)
题目取自Android源代码:final int N = a.getIndexCount();\nfor (int i = 0; i < N; i++) {\nint index = a.
补全结果如下:final int N = a.getIndexCount();
for (int i = 0; i < N; i++) {
int attr = a.getAttribute(i);
从上下文看,鬼知道a是个啥类型,但是这个模型可以根据变量attr猜出来getAttribute。
话说我的attr想用a.getIndex获取怎么办?不用重新训练了,给模型写个例子就好了:
输入如下:int attr = a.getIndex(i);nfor (int i = 0; i < N; i++) {nint attr = a.
补全的结果就是这样了:
int attr = a.getIndex(i);
for (int i = 0; i < N; i++) {
int attr = a.getIndex(i);
### 还会给变量名做加法!(Python, Keras)
输入如下:tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)ntower_1 = Conv2D(
见证奇迹的时刻到了:tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img) tower_2 = Conv2D(64
也就是补完tower_1之后,算法不过瘾开始命名了一个tower_2继续补!
这对卷积一写好多层太方便了有没有?
这个加法对于变量名管用,对于下标变量也有效。
我们再来看个例子:x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
不管是用y_train还是x_test做补全时,shape后面的[0]就会被加1变成[1],在这里是不适用的,补完了需要手工补一下。
### 多语言支持 (common lisp)
为了证明不是针对Java和Python做的特殊优化,我们来个lisp的例子看下:text = '(progn (setq a (func1 0)) (setq b'
输出如下:(progn (setq a (func1 0)) (setq b (func2 0)) (setq c (func3 0)) (setq d (func4 0))
不但知道func1加1变func2,setq的变量,也从b变成c,d以此类推。
## 30行代码创造奇迹
上面这样神奇的功能,我们借助最新的神经网络自然处理的工具,只有30多行代码就可以搞定:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
加载词汇表
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
输入待补全的文本
text = 'int idx = a.getIndex(i);nfor (int i = 0; i < N; i++) {nint attr = a.'
predicted_text = text
每一个只能补一个token出来,补一句话需要多次,30次是我拍脑袋的
for i in range(0,30):
# 以上次预测结果作为本次的输入,所谓的自回归
indexed_tokens = tokenizer.encode(predicted_text)
# 将读出的索引标记转化成PyTorch向量
tokens_tensor = torch.tensor([indexed_tokens])
# 加载模型中预训练好的权值
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 设置为eval模式,这样就不会执行训练模式下的Dropout过程
model.eval()
# 使用GPU进行加速,诚实地讲速度不太快
tokens_tensor = tokens_tensor.to('cuda')
model.to('cuda')
# 进行推理
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
# 获取预测的下一个子词
predicted_index = torch.argmax(predictions[0, -1, :]).item()
# 解码成我们都读懂的文本
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
# 打印输入结果
print(predicted_text)
## 用来自动写作
其实,上面所用的gpt-2模型,并不是给代码补全用的,用来自动写点的东西到时它的本业。
比如大家可以试试,给“To be or not to be"补全下,我的结果如下“To be or not to be, the only thing that matters is that you're a good person.”
再比如“I have a dream that one day”,我的结果如下“I have a dream that one day I will be able to live in a world where I can be a part of something bigger than myself.”
如果不想写代码的话,可以直接在[https://transformer.huggingface.co/doc/gpt2-large](https://transformer.huggingface.co/doc/gpt2-large)中去直接试验。
如下图所示,写代码写文字都可以:
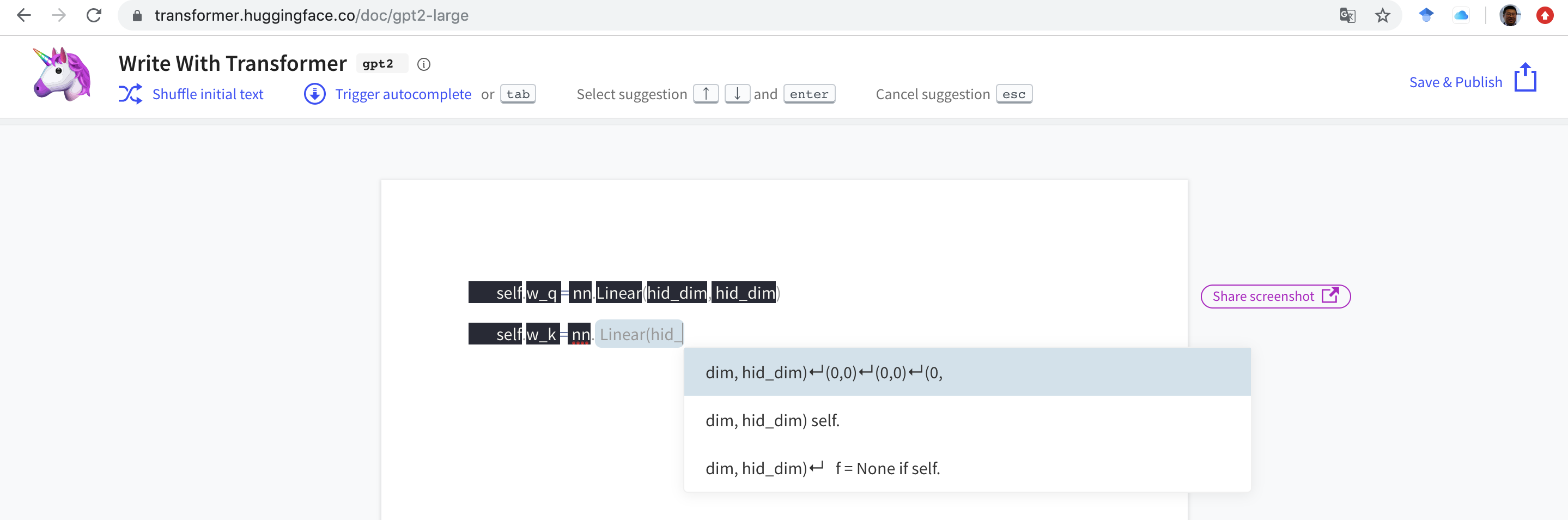
## 安装环境
如果想试用上面的代码的话,只需要安装transformers库就好了。
pip install transformers
另外,transformers库依赖PyTorch或Tensorflow之一,我们上面的代码是基于PyTorch的,还需要安装一下PyTorch:pip3 install torch torchvision
在Windows下安装命令稍有不同,需要指定版本号,例:pip3 install torch===1.3.0 torchvision===0.4.1 -f https://download.pytorch.org/whl/torch_stable.html