今天分享一篇开发小哥哥如何使用云监控和日志服务快速发现故障定位问题的经历。
事件起因
小哥哥正在Coding,突然收到云监控报警,说他的API调用RT过高,小哥哥的业务主要为线上服务提供数据查询,RT过高可能会导致大量页面数据空白,这还了得,赶紧查。
排查过程
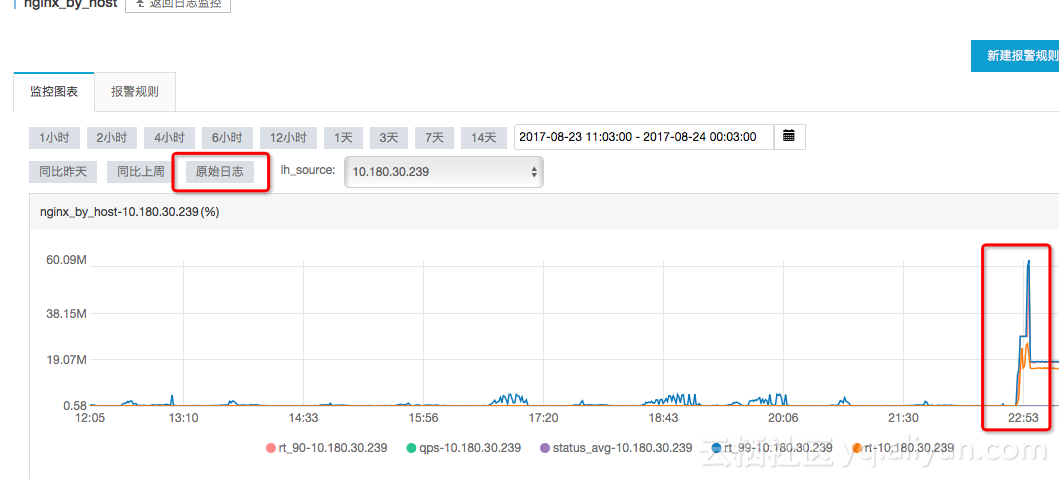
收到报警后查看指标趋势,发现突然RT突然增高。
查看单台机器维度的指标,发现30.239这台机器RT延时非常大。
-
具体机器的RT走势图:
 -
查看存储在日志服务的原始数据,查看发生问题时的原始日志,发生某一次请求的rt突然变的很大,之后的rt都变的很大。
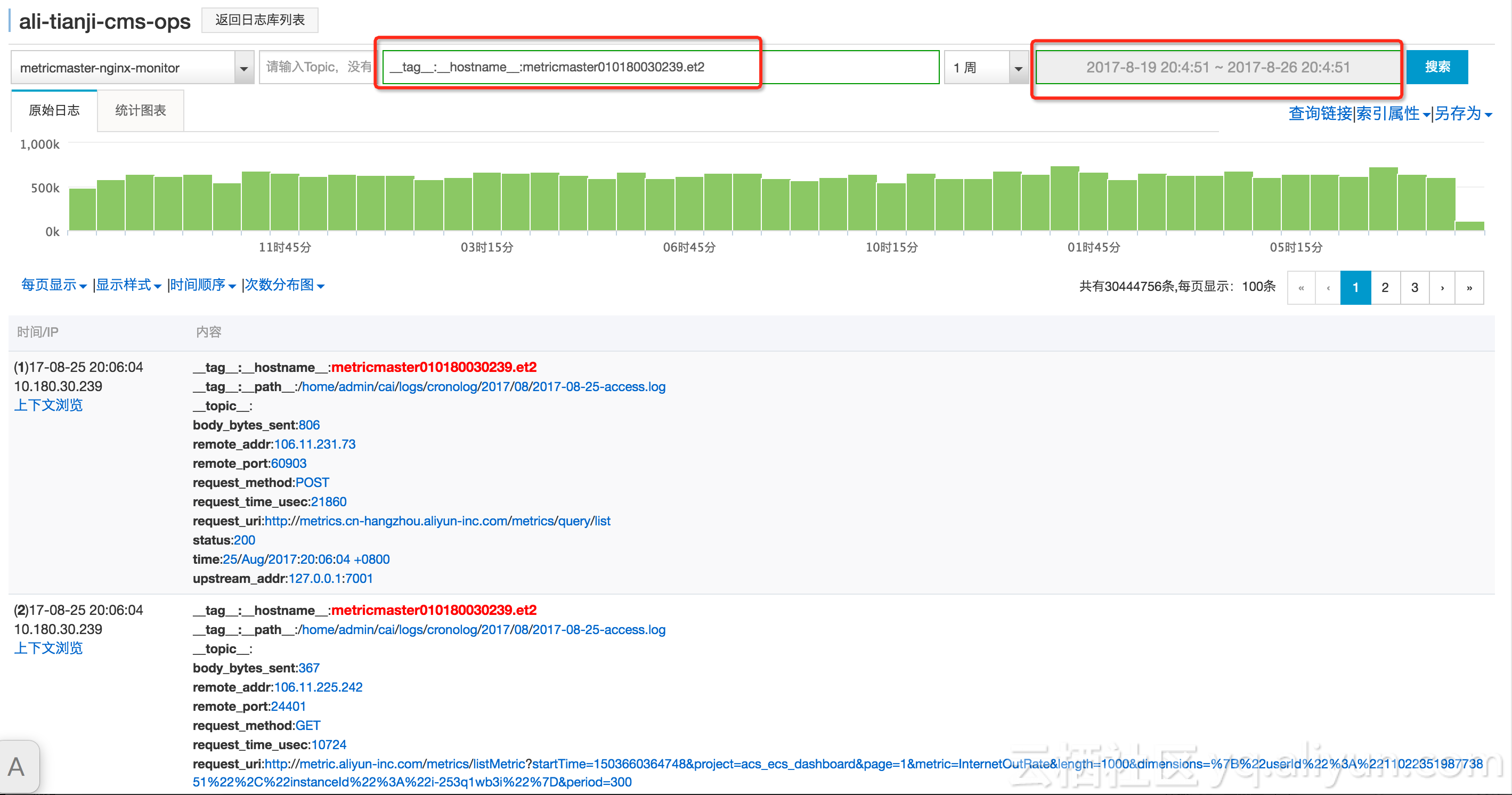 - 同时也收到了健康检查发出的30.239机器的业务java进程hang,端口telnet监控不通的报警。
于是去主机监控看这台机器到底出了什么问题。
- cpu,load,内存都在波动,网络有明显变化,流量暴增,tcp连接数先增先减
- 再看进程监控:发现机器上的主要的业务进程-java进程,指标变化异常,
登录服务器后,查看GC日志
发现在事发时,有大量的fullgc。导致进程hang住。出现以上一系列的现象
排查结果
故障结果
结合nginx日志和应用gc日志,再结合实际的业务场景,定位到在某一次大查询时,在内存hold住太多数据,导致内存爆掉,系统不断gc,进程hang住,进一步导致系统指标和进程指标的现象。
进一步发现和优化
通过jstat -gcutil pid1000查看,发现是perm区的fullgc非常多。通过jmap−permstatpid (要谨慎,不要线上做),发现google avaiator相关的类很多,想起使用了google的表达式引擎,看代码发现在compile的时候,没有加cache。
加上cache发布后,经过几天的观察,查询前端服务器的内存更加平稳,后台5xx的比例也更低。