@[TOC](总计和小计、逐行累计求和)
### 一、总计和小计使用函数
#### 1、rollup
group by 我们都知道,是一个分组函数,用于针对某一列做分组操作。
但是当它搭配其他的函数一起使用的时候,就像一对男女孩,撞出不一样的火花。
==rollup(字段1,字段2,.....)
rollup和group by一起使用,可以针对每一个分组返回一个小计行,以及为所有的分组返回一个总计行(一个字段就是返回总计行,多个字段就是返回每一个分组的一个小计行和一个总计行)==
实践是检验真理的唯一标准,那我们来实践一下,我们先来快速创建一个表。有多快,很快很快的那种。
```handlebars
CREATE TABLE EMP (
"EMPNO" NUMBER(4) NOT NULL ,
"ENAME" VARCHAR2(10 BYTE) ,
"JOB" VARCHAR2(9 BYTE) ,
"SAL" NUMBER(7,2) ,
"DEPTNO" NUMBER(2)
)
INSERT INTO "SCOTT"."EMP" VALUES (‘1‘, ‘张三‘, ‘开发‘, ‘10000‘, ‘10‘);
INSERT INTO "SCOTT"."EMP" VALUES (‘2‘, ‘李四‘, ‘运维‘, ‘6000‘, ‘20‘);
INSERT INTO "SCOTT"."EMP" VALUES (‘3‘, ‘王五‘, ‘测试‘, ‘6000‘, ‘30‘);
INSERT INTO "SCOTT"."EMP" VALUES (‘4‘, ‘麻子‘, ‘开发‘, ‘12000‘, ‘10‘);
```
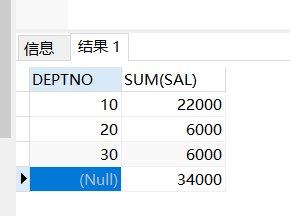
==当我们的rollup里面只有一个字段的时候,就返回一个总计行==
```handlebars
select deptno,sum(sal) from emp
group by rollup(deptno);
查询结果:
10 22000
20 6000
30 6000
34000
```
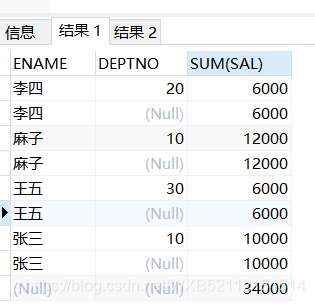
==当我们传递两个列字段的时候,就会按照第一个字段进行分组,返回一个小计行,最后返回一个总计行==
```handlebars
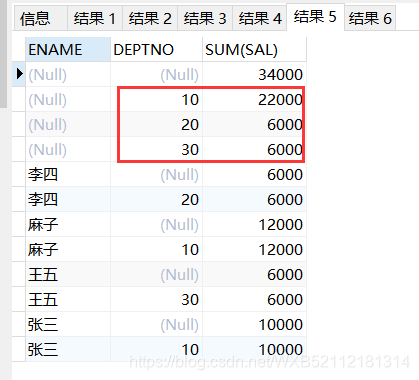
select ENAME,DEPTNO,sum(sal) from emp group by rollup(ENAME,DEPTNO);
李四 20 6000
李四 6000
麻子 10 12000
麻子 12000
王五 30 6000
王五 6000
张三 10 10000
张三 10000
34000
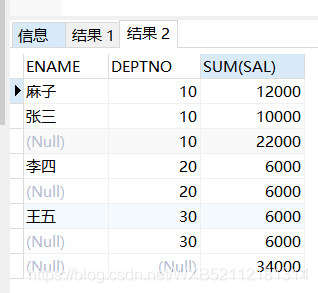
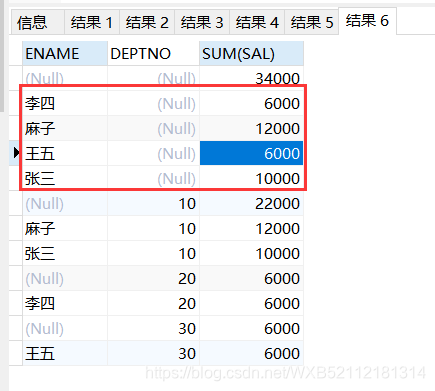
select ENAME,DEPTNO,sum(sal) from emp group by rollup(DEPTNO,ENAME);
麻子 10 12000
张三 10 10000
10 22000
李四 20 6000
20 6000
王五 30 6000
30 6000
34000
```
根据rollup()传入的第一个字段不同,返回的结果是不一样的。我的理解是,rollup()传递多字段的时候,会==先对多字段进行分组,然后对第一个字段进行分组==,比如上面的ename是第一个字段,多字段分组后就有四种,然后对第一字段分组后还剩四种,并且返回一个小计行,最后返回一个总计行
#### 2、cube
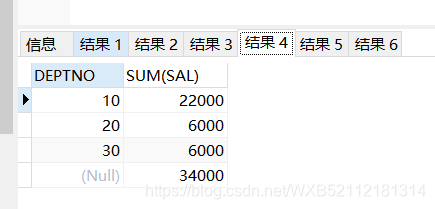
cube()传递一个字段的时候,和rollup是一样的结果
```handlebars
select DEPTNO,sum(sal) from emp group by cube(DEPTNO) order by deptno;
10 22000
20 6000
30 6000
34000
```
但是cube()传递多个字段的时候,就和rollup()不一样了,cube()对多字段的处理是先对所有的多字段进行分组,然后==对第一个字段进行分组,再对第二个字段进行分组,意思就是两种分组合起来了==,从下面的结果我们就可以看出来,比如第二个字段是deptno,分组后会把相同的10做为一组,所以可以看到根据ename分组会产生一个小计行,再根据deptno分组后产生了一个小计行,最后返回一个总计行。就等于在rollup()的基础上,我们多了几行分组的结果
```handlebars
select ENAME,DEPTNO,sum(sal) from emp group by cube(ENAME,DEPTNO);
34000
10 22000
20 6000
30 6000
李四 6000
李四 20 6000
麻子 12000
麻子 10 12000
王五 6000
王五 30 6000
张三 10000
张三 10 10000
select ENAME,DEPTNO,sum(sal) from emp group by cube(DEPTNO,ENAME);
34000
李四 6000
麻子 12000
王五 6000
张三 10000
10 22000
麻子 10 12000
张三 10 10000
20 6000
李四 20 6000
30 6000
王五 30 6000
```
#### 3、grouping
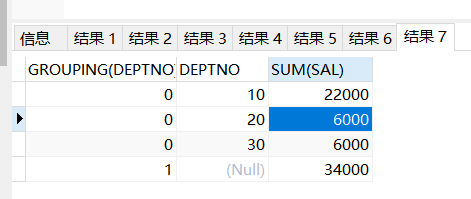
GROUPING函数可以接受一列,返回0或者1。==如果列值为空,那么GROUPING()返回1;如果列值非空,那么返回0==。GROUPING只能在使用ROLLUP或CUBE的查询中使用。我的理解就是==用来填充使用rollup()和cube()产生的null值==
```handlebars
select grouping(deptno),DEPTNO,sum(sal) from emp group by rollup(DEPTNO) ;
0 10 22000
0 20 6000
0 30 6000
1 34000
```
我们使用==decode函数或case when==来填充为null的值。
==DECODE(value,if 条件1,then 值1,if 条件2,then 值2,...,else 其他值)==
```handlebars
select decode(grouping(deptno),1,‘总计‘,DEPTNO) deptno,sum(sal) from emp group by rollup(DEPTNO) ;
10 22000
20 6000
30 6000
总计 34000
```
!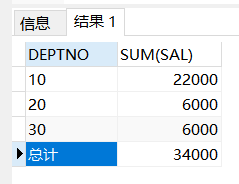
可以看到我们把第一次查询结果中的null填充了一个“总计”,这里使用的是rollup()配合,使用cube()也是一样的。
#### 4、grouping sets
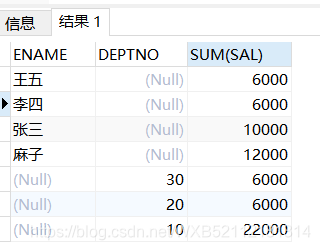
grouping sets()传递多字段就是分别对字段进行分组了,产生的结果就是多个字段分别分组后合起来的行。
```handlebars
select ENAME,DEPTNO,sum(sal) from emp group by grouping sets(ENAME,DEPTNO);
王五 6000
李四 6000
张三 10000
麻子 12000
30 6000
20 6000
10 22000
```
从结果我们可以看出,分别针对ename分组产生四行结果和对deptno分组产生三行结果。
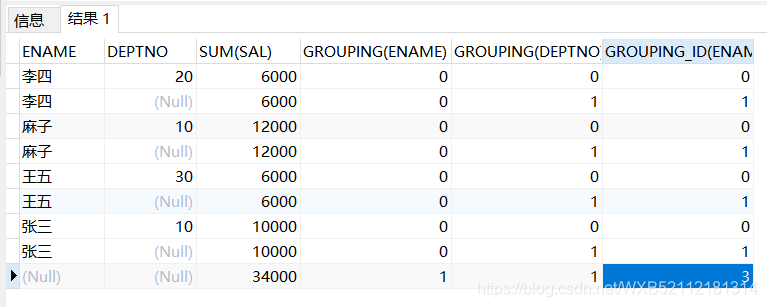
#### 5、grouping_id
grouping_id()配合grouping()函数使用,会根据grouping()的值来决定,比如==grouping(字段1)为0,grouping(字段2)为1,则grouping_id(字段1,字段2)的结果就是1,如果grouping(字段1)为1,grouping(字段2)为0,则grouping_id(字段1,字段2)的结果就是2,如果grouping(字段1)为1,grouping(字段2)为1,则grouping_id(字段1,字段2)的结果就是3,==
```handlebars
select ename,deptno,sum(sal),
grouping(ename),
grouping(deptno),
grouping_id(ename,deptno)
from emp group by rollup(ename,deptno) ;
李四 20 6000 0 0 0
李四 6000 0 1 1
麻子 10 12000 0 0 0
麻子 12000 0 1 1
王五 30 6000 0 0 0
王五 6000 0 1 1
张三 10 10000 0 0 0
张三 10000 0 1 1
34000 1 1 3
```
### 二、逐行累计求和方法(OVER函数)
#### 1、sum(字段) over(partition by 字段1 order by 字段2....)
==over(partition by 字段1 order by 字段2....)
按字段1指定的字段进行分组排序,或者说按字段字段2的值进行分组排序==
```handlebars
select deptno,sal,
sum(sal) over (partition by deptno order by deptno) 逐行累计求和
from emp;
10 10000 22000
10 12000 22000
20 6000 6000
30 6000 6000
select deptno,sal,
sum(sal) over ( order by deptno) 逐行累计求和
from emp
10 10000 22000
10 12000 22000
20 6000 28000
30 6000 34000
```
从上面的结果我们可以看出,加了==partition by deptno==就会根据指定字段分组逐行累加求和,否则全部逐行累加求和。