# 1. Numpy概述
~~~
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。大多数提供科学计算的包都是用NumPy的数组作为构建基础。
~~~

## 1.1.1. Why NumPy?
1.一个强大的N维数组对象ndarray,具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组
2.用于集成由C、C++、Fortran等语言类库的C语言 API
3.线性代数、随机数生成以及傅里叶变换功能。
4.用于对整组数据进行快速运算的标准数学函数(无需编写循环),支持大量的数据运算
5.是众多机器学习框架的基础库
~~~
Tips:Python的面向数组计算可以追溯到1995年,Jim Hugunin创建了Numeric库。接下来的10年,许多科学编程社区纷纷开始使用Python的数组编程,但是进入21世纪,库的生态系统变得碎片化了。2005年,Travis Oliphant从Numeric和Numarray项目整了出了NumPy项目,进而所有社区都集合到了这个框架下。
~~~
NumPy之于数值计算特别重要的原因之一,是因为它可以高效处理大数组的数据。这是因为:
~~~
NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环。
~~~
我们来直观感受一下numpy的运行速度:
```python
# 导入numpy
# 我们将依照标准的Numpy约定,即总是使用import numpy as np
# 当然你也可以为了不写np, 而直接在代码中使用from numpy import *,
# 但是建议你最好还是不要养成这样的坏习惯。
import numpy as np
# 生成一个numpy对象, 一个包含一百万整数的数组
np_arr = np.arange(1000000)
# 一个等价的Python列表:
py_list = list(range(1000000))
```
对各个序列分别平方操作(%time是ipython的特殊功能,用于测试语句运行的时间需要安装ipython, pip install ipython)
```python
%time for _ in range(10): np_arr2 = np_arr ** 2
```
CPU times: user 13.1 ms, sys: 5.62 ms, total: 18.8 ms Wall time: 17.7 ms
```python
%time for _ in range(10): py_list2 = [x ** 2 for x in py_list]
```
CPU times: user 3.06 s, sys: 173 ms, total: 3.24 s Wall time: 3.25 s 由上述代码可以看出,基于NumPy的算法要比纯Python快10到100倍(甚至更快),并且使用的内存更少
# 2. 创建ndarray
NumPy最重要的一个特点就是ndarray(N-dimensional array),即N维数组),该对象是一个快速而灵活的大数据集容器。你可以利用这种数组对整块数据执行一些数学运算,其语法跟标量元素之间的运算一样。
```python
# 创建numpy数组的方式
import numpy as np
```
```python
np.__version__
```
```python
'1.15.2'
```
```python
nparr = np.array([i for i in range(10)])
nparr
```
```python
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
```
```python
array([[11, 22, 33, 44],
[10, 20, 30, 40]])
```
## 2.1.1. arange创建数组
arange函数是python内置函数range函数的数组版本.
```python
# 产生0-9共10个元素
ndarray = np.arange(10)
ndarray
```
```python
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
```
```python
# 产生从10-19共10个元素
ndarray1 = np.arange(10, 20)
```
```python
# 产生10 12 14 16 18, 2为step
ndarray2 = np.arange(10, 20, 2)
ndarray2
```
```python
array([10, 12, 14, 16, 18])
```
```python
# ndarray2的形状
ndarray2.shape
```
```python
(5,)
```
## 2.1.2. 其他创建numpy数组的方式
**使用zeros和zeros_like创建数组**
用于创建数组,数组元素默认值是0. 注意:zeros_linke函数只是根据传入的ndarray数组的shape来创建所有元素为0的数组,并不是拷贝源数组中的数据.
```python
ndarray4 = np.zeros(10)
ndarray5 = np.zeros((3, 3))
ndarray6 = np.zeros_like(ndarray5) # 按照 ndarray5 的shape创建数组
# 打印数组元素类型
print("以下为数组类型:")
print('ndarray4:', type(ndarray4))
print('ndarray5:', type(ndarray5))
print('ndarray6:', type(ndarray6))
print("-------------")
print("以下为数组元素类型:")
print('ndarray4:', ndarray4.dtype)
print('ndarray5:', ndarray5.dtype)
print('ndarray6:', ndarray6.dtype)
print("-------------")
print("以下为数组形状:")
print('ndarray4:', ndarray4.shape)
print('ndarray5:', ndarray5.shape)
print('ndarray6:', ndarray6.shape)
```
~~~
以下为数组类型:
ndarray4: <class 'numpy.ndarray'>
ndarray5: <class 'numpy.ndarray'>
ndarray6: <class 'numpy.ndarray'>
-------------
以下为数组元素类型:
ndarray4: float64
ndarray5: float64
ndarray6: float64
-------------
以下为数组形状:
ndarray4: (10,)
ndarray5: (3, 3)
ndarray6: (3, 3)
~~~
**ones和ones_like创建数组**
```python
# 用于创建所有元素都为1的数组.ones_like用法同zeros_like用法.
# 创建数组,元素默认值是0
ndarray7 = np.ones(10)
ndarray7
```
```python
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
```
```python
ndarray8 = np.ones((3, 3))
```
```python
ndarray9 = np.ones_like(ndarray5) # 按照 ndarray5 的shape创建数组
ndarray9
```
```python
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
```
**empty和empty_like创建数组**
```python
ndarray10 = np.empty(5)
ndarray11 = np.empty((2, 3))
ndarray12 = np.empty_like(ndarray11)
ndarray12
```
```python
array([[7.e-323, 0.e+000, 0.e+000],
[0.e+000, 6.e-323, 0.e+000]])
```
**eye创建对角矩阵数组**
**该函数用于创建一个N*N的矩阵,对角线为1,其余为0.**
```python
ndarray13 = np.eye(5)
ndarray13
```
```python
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
```
```python
np.full((3, 5), 666)
```
```python
array([[666, 666, 666, 666, 666],
[666, 666, 666, 666, 666],
[666, 666, 666, 666, 666]])
```
# 3. ndarray的数据类型及索引
## 3.1.1. ndarray的数据类型
dtype(数据类型)是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息:
```python
In [33]: arr1 = np.array([1, 2, 3], dtype=np.float64)
In [34]: arr2 = np.array([1, 2, 3], dtype=np.int32)
In [35]: arr1.dtype
Out[35]: dtype('float64')
In [36]: arr2.dtype
Out[36]: dtype('int32')
```
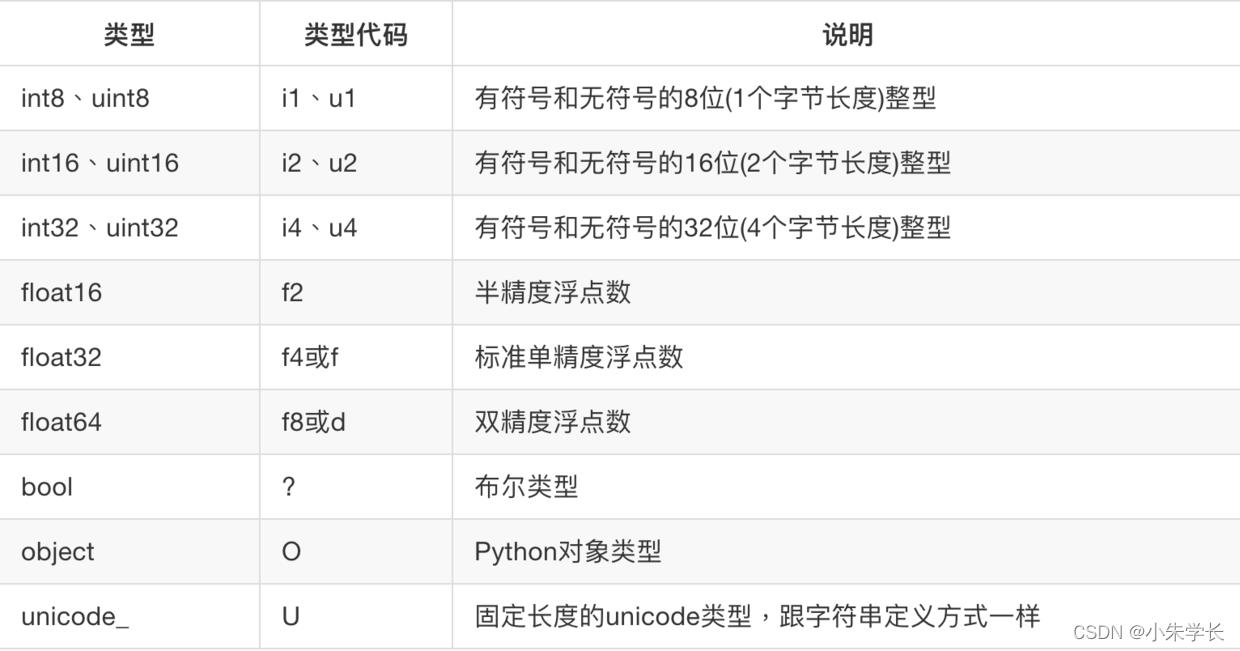
dtype是NumPy灵活交互其它系统的源泉之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码(如C、Fortran)”等工作变得更加简单。数值型dtype的命名方式相同:一个类型名(如float或int),后面跟一个用于表示各元素位长的数字。标准的双精度浮点值(即Python中的float对象)需要占用8字节(即64位)。因此,该类型在NumPy中就记作float64
~~~
Tips:记不住这些NumPy的dtype也没关系,新手更是如此。通常只需要知道你所处理的数据的大致类型是浮点数、复数、整数、布尔值、字符串,还是普通的Python对象即可。当你需要控制数据在内存和磁盘中的存储方式时(尤其是对大数据集),那就得了解如何控制存储类型。
你可以通过ndarray的astype方法明确地将一个数组从一个dtype转换成另一个dtype: ```In [37]: arr = np.array([1, 2, 3, 4, 5])
~~~
In [38]: arr.dtype Out[38]: dtype('int64')
In [39]: float_arr = arr.astype(np.float64)
In [40]: float_arr.dtype Out[40]: dtype('float64')
在本例中,整数被转换成了浮点数。如果将浮点数转换成整数,则小数部分将会被截取删除:
In [41]: arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [42]: arr Out[42]: array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [43]: arr.astype(np.int32) Out[43]: array([ 3, -1, -2, 0, 12, 10], dtype=int32)
如果某字符串数组表示的全是数字,也可以用astype将其转换为数值形式:
In [44]: numericstrings = np.array(['1.25', '-9.6', '42'], dtype=np.string)
In [45]: numeric_strings.astype(float) Out[45]: array([ 1.25, -9.6 , 42. ])
```python
> 注意:使用numpy.string_类型时,一定要小心,因为NumPy的字符串数据是大小固定的,发生截取时,不会发出警告。pandas提供了更多非数值数据的便利的处理方法
如果转换过程因为某种原因而失败了(比如某个不能被转换为float64的字符串),就会引发一个ValueError。这里,我比较懒,写的是float而不是np.float64;NumPy很聪明,它会将Python类型映射到等价的dtype上。
数组的dtype还有另一个属性:
```
> 注意:使用numpy.string_类型时,一定要小心,因为NumPy的字符串数据是大小固定的,发生截取时,不会发出警告。pandas提供了更多非数值数据的便利的处理方法
如果转换过程因为某种原因而失败了(比如某个不能被转换为float64的字符串),就会引发一个ValueError。这里,我比较懒,写的是float而不是np.float64;NumPy很聪明,它会将Python类型映射到等价的dtype上。
数组的dtype还有另一个属性:
In [46]: int_array = np.arange(10)
In [47]: calibers = np.array([.22, .270, .357, .380, .44, .50], dtype=np.float64)
In [48]: int_array.astype(calibers.dtype) Out[48]: array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
你还可以用简洁的类型代码来表示dtype:
In [49]: empty_uint32 = np.empty(8, dtype='u4')
In [50]: empty_uint32 Out[50]: array([ 0, 1075314688, 0, 1075707904, 0, 1075838976, 0, 1072693248], dtype=uint32)
> Tips :调用astype总会创建一个新的数组(一个数据的备份),即使新的dtype与旧的dtype相同。
NumPy数组的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。NumPy用户称其为矢量化(vectorization)。大小相等的数组之间的任何算术运算都会将运算应用到元素级:(不需要循环即可对数据进行批量运算,叫做矢量化运算. 不同形状的数组之间的算数运算,叫做广播,后面会介绍)
In [51]: arr = np.array([[1., 2., 3.], [4., 5., 6.]])
In [52]: arr Out[52]: array([[ 1., 2., 3.], [ 4., 5., 6.]])
In [53]: arr * arr Out[53]: array([[ 1., 4., 9.], [ 16., 25., 36.]])
In [54]: arr - arr Out[54]: array([[ 0., 0., 0.], [ 0., 0., 0.]])
数组与标量的算术运算会将标量值传播到各个元素:
In [55]: 1 / arr Out[55]: array([[ 1. , 0.5 , 0.3333], [ 0.25 , 0.2 , 0.1667]])
In [56]: arr ** 0.5 Out[56]: array([[ 1. , 1.4142, 1.7321], [ 2. , 2.2361, 2.4495]])
大小相同的数组之间的比较会生成布尔值数组:
In [57]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
In [58]: arr2 Out[58]: array([[ 0., 4., 1.], [ 7., 2., 12.]])
In [59]: arr2 > arr Out[59]: array([[False, True, False], [ True, False, True]], dtype=bool)
```python
# 数组索引和切片
Numpy数组的索引是一个内容丰富的主题,因为选取数据子集或单个元素的方式有很多。一维数组很简单。从表面上看,它们和Python列表的功能差不多。
### 数组索引和切片基本用法
import numpy as np
```
```python
# 小x可以表示成数学中的向量
x = np.arange(10)
x
```
```python
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
```
```python
# 大X表示矩阵
X = np.arange(15).reshape((3, 5))
X
```
```python
# 大X表示矩阵
X = np.arange(15).reshape((3, 5))
X
```
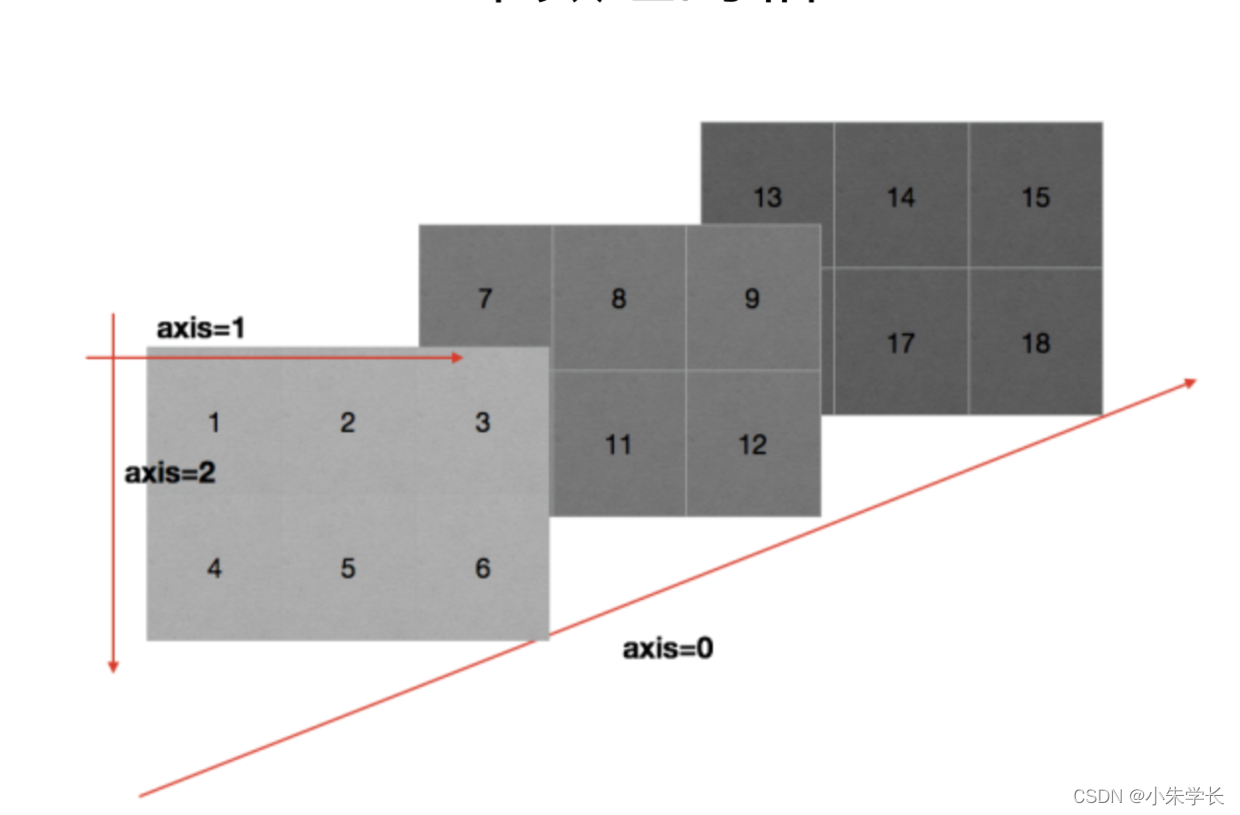
**二维数组**
下图说明了二维数组的索引方式。轴0作为行,轴1作为列。

**三维数组**
```python
# 访问x中值是1的元素
x[1]
```
```python
3
```
```python
# 赋值 损失了精度,截断操作
x[1] = 3.64
```
```python
x
```
```python
array([0, 3, 2, 3, 4, 5, 6, 7, 8, 9])
# 切片
```
```python
x[1:4]
```
```python
array([3, 2, 3])
```
```python
# 按照先行后列的访问方式
X[1][4]
```
```python
9
```
```python
# 第二种写法,推荐, 逗号前面是行索引,后面是列索引
X[1,4]
```
```python
9
```
```python
X[1,4] = 33
```
```python
X
```
```python
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 33],
[10, 11, 12, 13, 14]])
```
```python
X[1,4] = 33
X
```
```python
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 33],
[10, 11, 12, 13, 14]])
```
**numpy的特殊之处**
当把一个数字值赋值给一个切片时,该值会自动传播到整个选区。跟列表的区别在于,数组切片是原始数组的视图,这意味着数据不会被赋值,视图上的任何修改都会直接反应到源数组上.
大家可能对此感到不解,由于Numpy被设计的目的是处理大数据,如果Numpy将数据复制来复制去的话会产生何等的性能和内存问题.
如果要得到一个切片副本的话,必须显式进行复制操作.
```python
# 切片赋值
x[3:6] = 12
x
array([ 0, 3, 2, 12, 12, 12, 6, 7, 8, 9])
arr_slice = x[3:6]
# 对切片的值进行修改,也会体现到原数组身上
arr_slice[0] = 999
arr_slice
array([999, 666, 666])
arr_slice[:] =666
x
array([ 0, 3, 2, 666, 666, 666, 6, 7, 8, 9])
# 如果你还是想要数组切片的拷贝而不是一份视图的话,可以进行如下操作
X[:2, 2:4].copy()
array([[2, 3],
[7, 8]])
```
## 3.1.2. Fancy indexing花式索引
花式索引是一个NumPy术语,它指的是利用整数数组进行索引
```python
arr = np.empty((8, 4))
```
```python
for i in range(8):
arr[i] = i
```
```python
arr
```
```python
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
```
```python
# 为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可
arr[[4, 3, 0, 6]]
```
```python
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
```
```python
# 这段代码确实达到我们的要求了!使用负数索引将会从末尾开始选取行
arr[[-3, -5, -7]]
```
```python
# 这段代码确实达到我们的要求了!使用负数索引将会从末尾开始选取行
arr[[-3, -5, -7]]
```
```python
# 一次传入多个索引数组会有一点特别。它返回的是一个一维数组,其中的元素对应各个索引元组
arr = np.arange(32).reshape((8, 4))
arr
```
```python
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
```
```python
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
```
```python
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
```
最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2)。无论数组是多少维的,花式索引总是一维的。
这个花式索引的行为可能会跟某些用户的预期不一样,选取矩阵的行列子集应该是矩形区域的形式才对。下面是得到该结果的一个办法:
```python
arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
```
```python
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
```
记住,花式索引跟切片不一样,它总是将数据复制到新数组中。
## 3.1.3. 布尔型索引
来看这样一个例子,假设我们有一个用于存储数据的数组以及一个存储姓名的数组(含有重复项)。在这里,我将使用numpy.random中的randn函数生成一些正态分布的随机数据:
```python
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
names
```
```python
array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
```
```python
array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
```
```python
array([[ 0.37370083, -0.33013143, -1.92042758, 0.61234423],
[-1.33734942, 0.29967533, 0.24341654, -1.17391872],
[-2.28175004, 0.03064196, -1.17277248, 0.174594 ],
[-0.5281719 , -0.2502034 , -0.88710013, -1.49036329],
[-0.72162151, 0.48662607, -2.25498875, 0.84092399],
[-0.58559699, -1.82182432, 1.73469502, 0.54399163],
[ 0.14997894, 1.72946463, 1.47252027, -1.79768056]])
```
假设每个名字都对应data数组中的一行,而我们想要选出对应于名字"Bob"的所有行。跟算术运算一样,数组的比较运算(如==)也是矢量化的。因此,对names和字符串"Bob"的比较运算将会产生一个布尔型数组:
```python
names == 'Bob'
array([ True, False, False, True, False, False, False])
```
这个布尔型数组可用于数组索引:
```python
data[names == 'Bob'] # 实际上选的是第1行和第4行的筛选
array([[ 0.37370083, -0.33013143, -1.92042758, 0.61234423],
[-0.5281719 , -0.2502034 , -0.88710013, -1.49036329]])
# 如果布尔型数组的长度不对,布尔型选择就会出错,因此一定要小心。
# 下面的例子,我选取了names == 'Bob'的行,并索引了列:
data[names == 'Bob', 2:]
array([[-1.92042758, 0.61234423],
[-0.88710013, -1.49036329]])
# 要选择除"Bob"以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定:
names != 'Bob'
array([False, True, True, False, True, True, True])
data[~(names == 'Bob')]
array([[-1.33734942, 0.29967533, 0.24341654, -1.17391872],
[-2.28175004, 0.03064196, -1.17277248, 0.174594 ],
[-0.72162151, 0.48662607, -2.25498875, 0.84092399],
[-0.58559699, -1.82182432, 1.73469502, 0.54399163],
[ 0.14997894, 1.72946463, 1.47252027, -1.79768056]])
```
使用布尔类型数组设置值是一种经常用到的手段
```python
import numpy as np
ndarray1 = np.arange(5)
ndarray1
array([0, 1, 2, 3, 4])
ndarray2 = np.arange(16).reshape((4, 4))
ndarray2
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
names = np.array(['aaa', 'bbb', 'ccc', 'ddd'])
names
array(['aaa', 'bbb', 'ccc', 'ddd'], dtype='<U3')
# 将数组ndarray1中所有大于2的元素设置成8
ndarray1[ndarray1 > 2] = 8
ndarray1
array([0, 1, 2, 8, 8])
# 将ndarray2的aaa这一行所有的元素设置为0
ndarray2[names == 'aaa'] = 0
# 将ndarray2的bbb这一行2位置往后所有的元素设置为1
ndarray2[names == 'bbb', 2:] = 666
ndarray2
array([[ 0, 0, 0, 0],
[ 4, 5, 666, 666],
[ 8, 9, 10, 11],
[ 12, 13, 14, 15]])
# 将ndarray2的ccc ddd这2行所有的元素设置为2
ndarray2[(names == 'ccc') | (names == 'ddd')] = 999
ndarray2
array([[ 0, 0, 0, 0],
[ 4, 5, 666, 666],
[999, 999, 999, 999],
[999, 999, 999, 999]])
```
# 4. 数组函数
## 4.1.1. 通用函数:快速的元素级数组函数
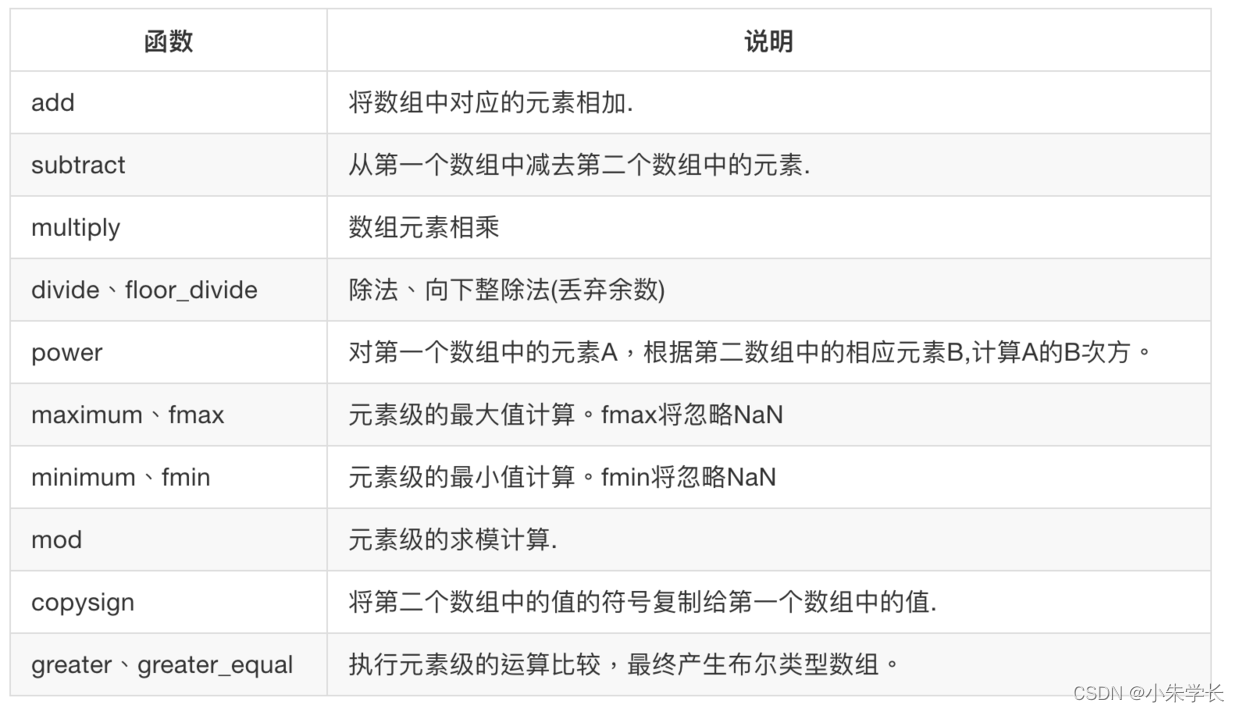
通用函数(即universal function)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。 许多ufunc都是简单的元素级变体,如sqrt和exp:
**常用一元ufunc:**

**常用二元ufunc:**
```python
import numpy as np
ndarray1 = np.array([3.5, 1.7, 2.2, -7.8, np.nan, 4.6, -3.4])
ndarray1
array([ 3.5, 1.7, 2.2, -7.8, nan, 4.6, -3.4])
# abs 计算整数、浮点数的绝对值。
np.abs(ndarray1)
array([3.5, 1.7, 2.2, 7.8, nan, 4.6, 3.4])
# square计算各元素的平方根。相当于arr ** 0.5
np.square(ndarray1)
array([12.25, 2.89, 4.84, 60.84, nan, 21.16, 11.56])
# sign 计算各元素的正负号,1(正数)、0(零)、-1(负数)
np.sign(ndarray1)
array([ 1., 1., 1., -1., nan, 1., -1.])
# ceil 计算各元素的celling值,即大于该值的最小整数。
np.ceil(ndarray1)
array([ 4., 2., 3., -7., nan, 5., -3.])
# floor 计算各元素的floor值,即小于等于该值的最大整数。
np.floor(ndarray1)
array([ 3., 1., 2., -8., nan, 4., -4.])
# rint 将各元素值四舍五入到最近的整数,保留dtype
np.rint(ndarray1)
array([ 4., 2., 2., -8., nan, 5., -3.])
# isnan 返回一个表示“那些是NaN(这不是一个数字)”的布尔类型数组.
np.isnan(ndarray1)
array([False, False, False, False, True, False, False])
```
**二元运算符**
```python
ndarray2 = np.random.randint(1, 20, (4, 5))
ndarray3 = np.random.randint(-10, 10, (4, 5))
ndarray3 = np.where(ndarray3 == 0, 1, ndarray3)
# add 将数组中对应的元素相加.
np.add(ndarray2, ndarray3)
array([[15, 10, 6, 24, 5],
[ 8, 4, 6, -6, 9],
[ 9, 9, 4, 16, 12],
[ 9, 16, 14, 1, 5]])
# subtract 从第一个数组中减去第二个数组中的元素.
np.subtract(ndarray2, ndarray3)
array([[17, 22, -2, 6, -1],
[26, 6, 20, 10, -3],
[25, 5, 22, 20, 8],
[13, 14, -2, 7, 11]])
# maximum、fmax 从两个数组中取出最大值。fmax将忽略NaN
np.maximum(ndarray2, ndarray3)
array([[16, 16, 4, 15, 3],
[17, 5, 13, 2, 6],
[17, 7, 13, 18, 10],
[11, 15, 8, 4, 8]])
# mod 元素级的求模计算.相当于Python模运算符``x1%x2``,并且与除数x2具有相同的符号.
np.mod(ndarray2, ndarray3)
array([[ 0, -2, 2, 6, 2],
[-1, 0, -1, -6, 3],
[-7, 1, -5, 0, 0],
[-1, 0, 6, -2, -1]])
# copysign 将第二个数组中的值的符号复制给第一个数组中的值.
np.copysign(ndarray2, ndarray3)
array([[-16., -16., 2., 15., 2.],
[-17., -5., -13., -2., 3.],
[-17., 7., -13., -18., 10.],
[-11., 15., 6., -4., -8.]])
# greater、greater_equal 执行元素级的运算比较,最终产生布尔类型数组。
np.greater(ndarray2, ndarray3)
array([[ True, True, False, True, False],
[ True, True, True, True, False],
[ True, True, True, True, True],
[ True, True, False, True, True]])
```
可以通过数组上的一组数学函数对整个数组或某些数据进行统计计算。 基本的数组统计方法:
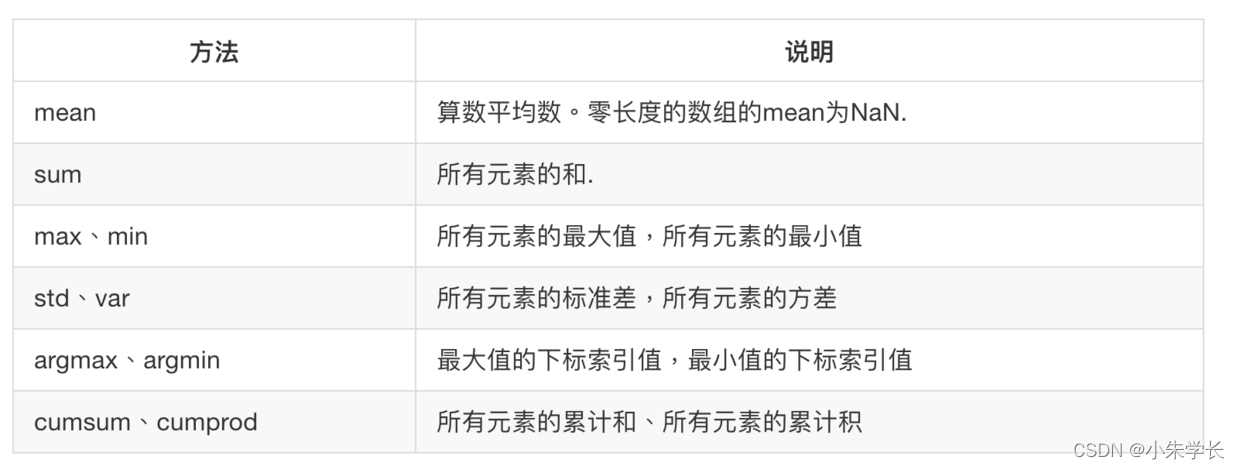
多维数组默认统计全部维度,axis参数可以按指定轴心统计,值为0则按列统计,值为1则按行统计。
```python
import numpy as np
ndarray1 = np.random.randint(1, 10, (4, 5))
ndarray1
array([[4, 7, 3, 3, 4],
[6, 6, 1, 3, 4],
[8, 8, 8, 2, 8],
[8, 9, 8, 3, 7]])
```
**sum求元素和**
```python
# 0-列 1-行
# sum-计算所有元素和
np.sum(ndarray1)
110
# sum-计算每一列的元素和
np.sum(ndarray1, axis=0)
array([26, 30, 20, 11, 23])
# sum-计算每一行的元素和
np.sum(ndarray1, axis=1)
array([21, 20, 34, 35])
```
**argmax求最大值索引**
```python
# argmax-默认情况下按照一维数组索引
np.argmax(ndarray1)
16
# argmax-统计每一列最大
np.argmax(ndarray1, axis=0)
array([2, 3, 2, 0, 2])
# argmax-统计每一行最大
np.argmax(ndarray1, axis=1)
array([1, 0, 0, 1])
```
```python
mean求平均数
# mean-求所有元素的平均值
np.mean(ndarray1)
5.5
# mean-求每一列元素的平均值
np.mean(ndarray1, axis=0)
array([6.5 , 7.5 , 5. , 2.75, 5.75])
# mean-求每一行元素的平均值
np.mean(ndarray1, axis=1)
array([4.2, 4. , 6.8, 7. ])
cumsum求元素累计和
# cumsum-前面元素的累计和
np.cumsum(ndarray1)
array([ 4, 11, 14, 17, 21, 27, 33, 34, 37, 41, 49, 57, 65,
67, 75, 83, 92, 100, 103, 110])
# cumsum-每一列元素的累计和
np.cumsum(ndarray1, axis=0)
array([[ 4, 7, 3, 3, 4],
[10, 13, 4, 6, 8],
[18, 21, 12, 8, 16],
[26, 30, 20, 11, 23]])
# cumsum-每一行元素的累计和
np.cumsum(ndarray1, axis=1)
array([[ 4, 11, 14, 17, 21],
[ 6, 12, 13, 16, 20],
[ 8, 16, 24, 26, 34],
[ 8, 17, 25, 28, 35]])
4.1.3. all和any函数
import numpy as np
# 判断两个数组元素是否相等
ndarray1 = np.arange(6).reshape((2, 3))
ndarray2 = np.arange(6).reshape((2, 3))
ndarray2
array([[0, 1, 2],
[3, 4, 5]])
ndarray3 = np.array([[ 0, 1, 2], [ 8, 9, 10]])
ndarray3
array([[ 0, 1, 2],
[ 8, 9, 10]])
(ndarray1 == ndarray2).all()
True
(ndarray1 == ndarray3).all()
False
(ndarray1 == ndarray3).any()
True
```
## 4.1.4. 添加和删除函数

```python
reshape:有返回值,即不对原始多维数组进行修改; resize:无返回值,即会对原始多维数组进行修改;
import numpy as np
ndarray1 = np.arange(4)
ndarray2 = np.arange(4)
ndarray2
array([0, 1, 2, 3])
ndarray3 = np.arange(12).reshape((3, 4))
ndarray3
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
```
```python
append数组中追加元素
# 数组追加一个数值元素
print(ndarray1)
np.append(ndarray1, 100)
[0 1 2 3]
array([ 0, 1, 2, 3, 100])
# 在一维数组后追加一维数组
print(ndarray2)
np.append(ndarray1, ndarray2)
[0 1 2 3]
array([0, 1, 2, 3, 0, 1, 2, 3])
# 在二维数组后追加标量元素
print(ndarray3)
np.append(ndarray3, 100)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 100])
# append总是返回一维数组
np.append(ndarray1, ndarray3)
array([ 0, 1, 2, 3, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
concatenate合并两个数组元素
ndarray4 = np.arange(12).reshape((3, 4))
ndarray4
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 合并两个一维数组
np.concatenate((ndarray1, ndarray2))
array([0, 1, 2, 3, 0, 1, 2, 3])
# 合并两个二维数组
np.concatenate((ndarray3, ndarray4), axis=0)
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
# 合并两个二维数组
np.concatenate((ndarray3, ndarray4), axis=1)
array([[ 0, 1, 2, 3, 0, 1, 2, 3],
[ 4, 5, 6, 7, 4, 5, 6, 7],
[ 8, 9, 10, 11, 8, 9, 10, 11]])
delete删除一行或者一列数组元素
ndarray5 = np.arange(20).reshape((4, 5))
ndarray5
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
# 删除第0行元素
np.delete(ndarray5, 0, axis=0)
array([[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
# 删除第2列元素
np.delete(ndarray5, 1, axis=1)
array([[ 0, 2, 3, 4],
[ 5, 7, 8, 9],
[10, 12, 13, 14],
[15, 17, 18, 19]])
# 删除第0、2、3列元素
np.delete(ndarray5, [0, 2, 3], axis=1)
array([[ 1, 4],
[ 6, 9],
[11, 14],
[16, 19]])
# 使用np.s_[::]创建切片对象
# 删除从1、2列元素
np.delete(ndarray5, np.s_[1:3], axis=1)
array([[ 0, 3, 4],
[ 5, 8, 9],
[10, 13, 14],
[15, 18, 19]])
insert插入元素
# 在第2个位置插入元素100
ndarray6 = np.arange(4)
print(ndarray6)
np.insert(ndarray6, 1, 100)
[0 1 2 3]
array([ 0, 100, 1, 2, 3])
# 在第3个位置插入两个元素10、20
np.insert(ndarray6, 2, [10, 20])
array([ 0, 1, 10, 20, 2, 3])
# 在第2行插入一行元素
np.insert(ndarray6, 1, np.array([100, 200, 300, 400]), axis=0)
array([ 0, 100, 200, 300, 400, 1, 2, 3])
# 在第3列插入一列元素
ndarray7 = np.arange(12).reshape((3, 4))
np.insert(ndarray7, 2, np.array([100, 200, 300]), axis=1)
array([[ 0, 1, 100, 2, 3],
[ 4, 5, 200, 6, 7],
[ 8, 9, 300, 10, 11]])
```
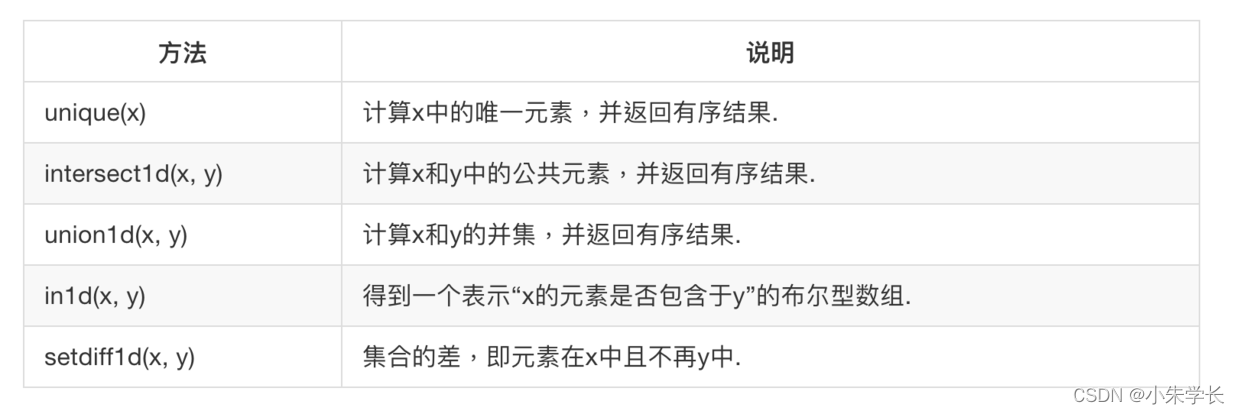
# 5. 唯一化和集合函数
Numpy提供了一些针对一维ndarray的基本集合运算。最常用的就是np.unique了,它用于找出数组中的唯一值并返回已排序的结果。
```python
唯一化
import numpy as np
names = np.array(['aaa', 'bbb', 'ccc', 'aaa', 'ddd', 'eee', 'ccc'])
ndarray1 = np.random.randint(1, 5, 10)
ndarray2 = np.random.randint(1, 5, (3, 4))
ndarray1
array([3, 4, 3, 3, 2, 1, 3, 3, 3, 2])
ndarray2
array([[4, 2, 3, 4],
[1, 2, 3, 1],
[3, 4, 4, 2]])
np.unique(names)
array(['aaa', 'bbb', 'ccc', 'ddd', 'eee'], dtype='<U3')
计算两个数组交集
np.unique(names)
array(['aaa', 'bbb', 'ccc', 'ddd', 'eee'], dtype='<U3')
np.unique(ndarray1)
array([1, 2, 3, 4])
ndarray3 = np.arange(1, 10)
ndarray4 = np.arange(5, 15)
ndarray3
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
ndarray4
array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
np.intersect1d(ndarray3, ndarray4)
array([5, 6, 7, 8, 9])
计算两个数组并集
ndarray5 = np.arange(1, 10)
ndarray6 = np.arange(5, 15)
ndarray5
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
ndarray6
array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
np.union1d(ndarray5, ndarray6)
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
数组中的元素是否在另一个数组中存在
ndarray7 = np.arange(1, 6)
ndarray8 = np.arange(3, 8)
ndarray7
array([1, 2, 3, 4, 5])
ndarray8
array([3, 4, 5, 6, 7])
np.in1d(ndarray7, ndarray8)
array([False, False, True, True, True])
计算两个数组的差集
ndarray9 = np.arange(1, 6)
ndarray10 = np.arange(3, 8)
ndarray9
array([1, 2, 3, 4, 5])
ndarray10
array([3, 4, 5, 6, 7])
np.intersect1d(ndarray9, ndarray10)
array([3, 4, 5])
np.setdiff1d(ndarray9, ndarray10)
array([1, 2])
```
## 5.1.1. 随机数生成函数
numpy.random模块对Python内置的random进行了补充。我们使用numpy.random可以很方便根据需要产生大量样本值。而python内置的random模块则一次生成一个样本值.

下图简单回忆一下均匀分布和正态分布
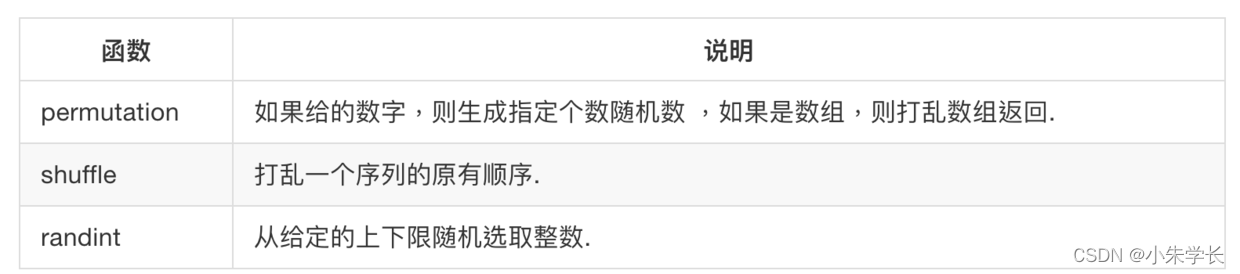
```python
import numpy as np
ndarray1 = np.arange(10)
np.random.permutation(5)
array([0, 1, 3, 4, 2])
np.random.permutation(ndarray1)
array([5, 8, 4, 2, 6, 1, 0, 7, 9, 3])
np.random.shuffle(ndarray1)
ndarray1
array([7, 3, 0, 6, 8, 1, 9, 5, 4, 2])
np.random.randint(10, 20)
12
np.random.randint(10, 20, 20)
array([13, 12, 15, 11, 19, 16, 14, 19, 18, 17, 12, 13, 10, 13, 16, 10, 12,
14, 18, 12])
np.random.randint(10, 20, (3, 4))
array([[19, 13, 14, 15],
[16, 18, 16, 13],
[17, 16, 18, 10]])
```
# 6. 数组排序函数
```python
对一维数组排序
import numpy as np
ndarray1 = np.random.randint(1, 10, (1, 5))
ndarray1
array([[4, 6, 7, 5, 4]])
ndarray1.sort()
ndarray1
array([[4, 4, 5, 6, 7]])
对二维数组排序
ndarray2 = np.random.randint(1, 10, (5, 5))
ndarray2
array([[8, 1, 3, 3, 7],
[9, 3, 5, 5, 8],
[4, 7, 9, 6, 1],
[9, 4, 1, 2, 8],
[8, 7, 6, 6, 4]])
# 对每行数据进行排序
ndarray2.sort()
ndarray2
array([[1, 3, 3, 7, 8],
[3, 5, 5, 8, 9],
[1, 4, 6, 7, 9],
[1, 2, 4, 8, 9],
[4, 6, 6, 7, 8]])
# 对每列数据进行排序
ndarray2.sort(axis=0)
ndarray2
array([[1, 2, 3, 7, 8],
[1, 3, 4, 7, 8],
[1, 4, 5, 7, 9],
[3, 5, 6, 8, 9],
[4, 6, 6, 8, 9]])
ndarray3 = np.sort(ndarray2) # 返回排序副本,源数据不变
ndarray3
array([[1, 2, 3, 7, 8],
[1, 3, 4, 7, 8],
[1, 4, 5, 7, 9],
[3, 5, 6, 8, 9],
[4, 6, 6, 8, 9]])
argsort函数(很重要) argsort函数返回的是数组值从小到大的索引值
import numpy as np
x = np.arange(10)
x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.random.shuffle(x)
x
array([3, 7, 9, 5, 6, 1, 0, 2, 4, 8])
np.argsort(x)
array([6, 5, 7, 0, 8, 3, 4, 1, 9, 2])
```
# 7. 广播
广播(broadcasting)指的是不同形状的数组之间的算术运算的执行方式。它是一种非常强大的功能,但也容易令人误解,即使是经验丰富的老手也是如此。将标量值跟数组合并时就会发生最简单的广播:
```python
import numpy as np
arr = np.arange(5)
arr
array([0, 1, 2, 3, 4])
arr * 4
array([ 0, 4, 8, 12, 16])
```
这里我们说:在这个乘法运算中,标量值4被广播到了其他所有的元素上。
看一个例子,我们可以通过减去列平均值的方式对数组的每一列进行距平化处理。这个问题解决起来非常简单:
```python
arr = np.random.randn(4, 3)
arr
array([[ 1.14072113e+00, -3.75330408e-01, 1.07997253e+00],
[ 2.92296713e-01, 5.19115583e-01, 1.29876898e+00],
[-1.12729644e+00, 1.30713095e+00, -4.75432622e-01],
[-2.30075456e-01, 2.16281589e+00, 1.92077343e-03]])
arr.mean(0)
array([0.01891149, 0.903433 , 0.47630741])
demeaned = arr - arr.mean(0)
demeaned
array([[ 1.12180965, -1.27876341, 0.60366511],
[ 0.27338522, -0.38431742, 0.82246156],
[-1.14620793, 0.40369794, -0.95174004],
[-0.24898694, 1.25938289, -0.47438664]])
demeaned.mean(0)
array([-6.93889390e-18, 0.00000000e+00, -2.77555756e-17])
```
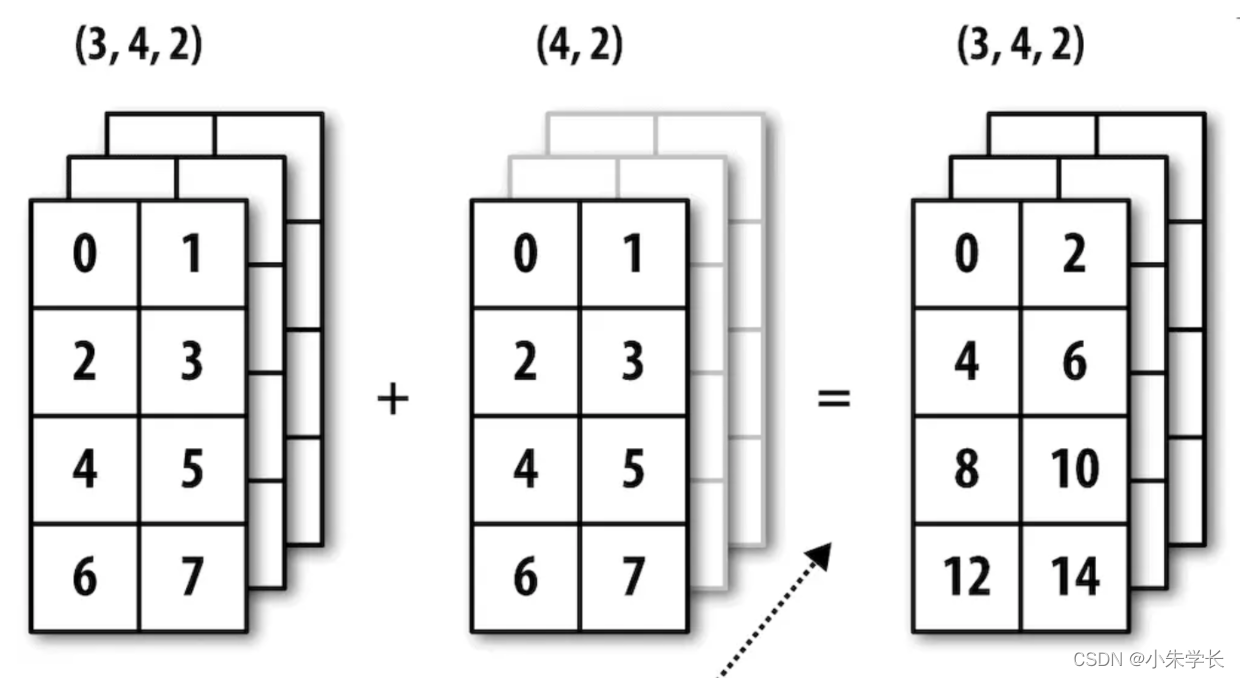
下图形象地展示了该过程。用广播的方式对行进行距平化处理会稍微麻烦一些。幸运的是,只要遵循一定的规则,低维度的值是可以被广播到数组的任意维度的(比如对二维数组各列减去行平均值)。

**广播原则**

画张图并想想广播的原则。再来看一下最后那个例子,假设你希望对各行减去那个平均值。由于arr.mean(0)的长度为3,所以它可以在0轴向上进行广播:因为arr的后缘维度是3,所以它们是兼容的。根据该原则,要在1轴向上做减法(即各行减去行平均值),较小的那个数组的形状必须是(4,1):
```python
arr
array([[ 1.14072113e+00, -3.75330408e-01, 1.07997253e+00],
[ 2.92296713e-01, 5.19115583e-01, 1.29876898e+00],
[-1.12729644e+00, 1.30713095e+00, -4.75432622e-01],
[-2.30075456e-01, 2.16281589e+00, 1.92077343e-03]])
row_means = arr.mean(1)
row_means
array([ 0.61512108, 0.70339376, -0.0985327 , 0.64488707])
row_means.shape
(4,)
row_means.reshape((4, 1))
array([[ 0.61512108],
[ 0.70339376],
[-0.0985327 ],
[ 0.64488707]])
demeaned = arr - row_means.reshape((4, 1))
demeaned
array([[ 0.52560005, -0.99045149, 0.46485144],
[-0.41109705, -0.18427818, 0.59537522],
[-1.02876373, 1.40566365, -0.37689992],
[-0.87496253, 1.51792882, -0.6429663 ]])
demeaned.mean(1)
array([ 0.00000000e+00, -3.70074342e-17, 5.55111512e-17, 0.00000000e+00])
```
**下图说明了该运算的过程**
二维数组在轴1上的广播
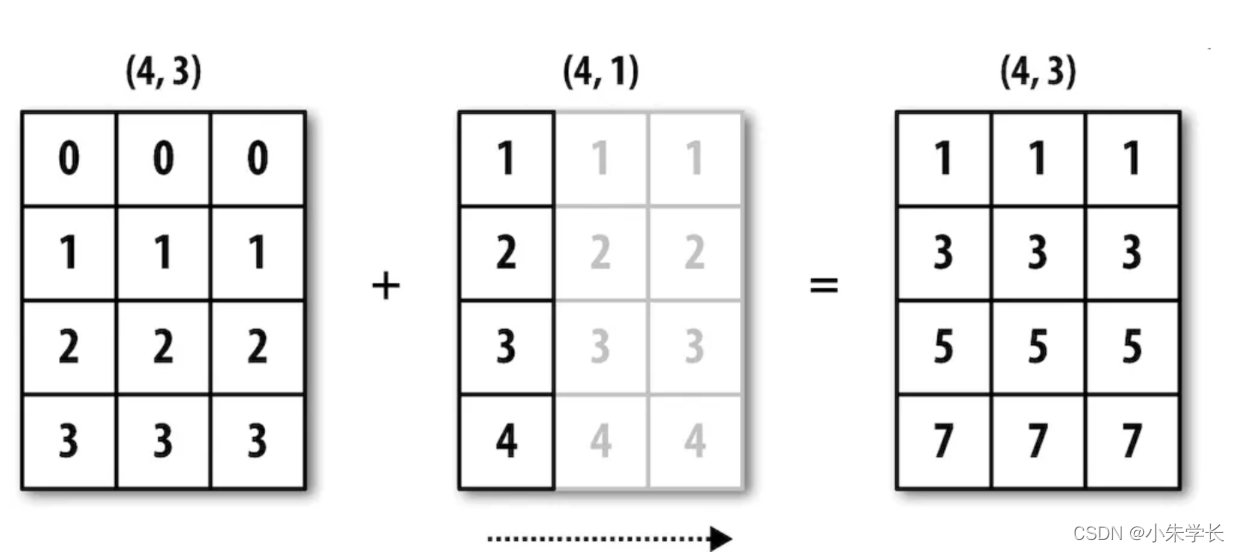
下图展示了另外一种情况,这次是在一个三维数组上沿0轴向加上一个二维数组。 三维数组在轴0上的广播