实战|用可视化方式看新闻,迅速了解最新时事热点
今天教大家如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里爬取了**2500**条新闻数据进行演示。

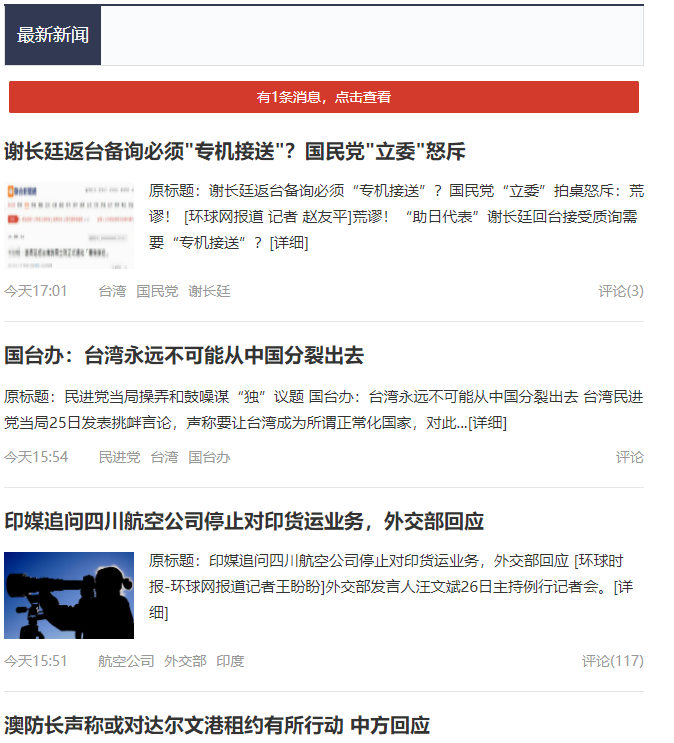
PS:这里采集的主要是国内最新新闻数据。先来看一下数据:

# 1、网页分析
在开始采集之前先说一下新闻数据来源(新浪网)
```
https://news.sina.com.cn/china/
```
### 下一页分析
我们想要采集多条数据,因此需要找到下一页的规律

点击第二页的时候,发现网页链接没有变化,这里数据是通过异步加载过来,因此查看network,找到了目标异步链接:
```
https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8&callback=feedCardJsonpCallback&_=1619440444354
```
但发现callback=feedCardJsonpCallback&_=1619440444354,可以去掉,因此最终链接如下:
```
https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8
```
参数page是页数,经过测试page范围在1~125,到126的时候就请求到的是空数据。每一页一共有20条,因此一共是**2500**条新闻数据。
### json数据结构
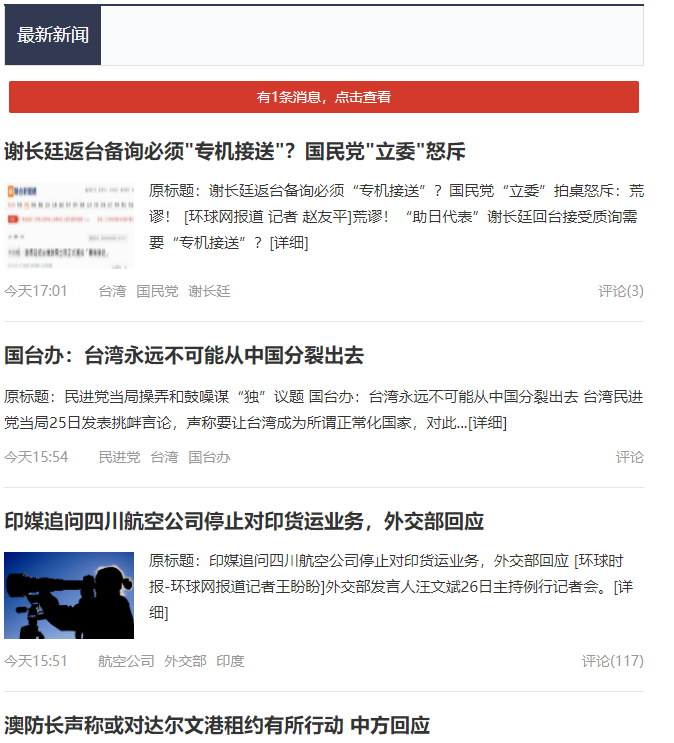

这里咱们学院获取三个字段(标题title、原标题intro、关键词keywords)
# 2、采集数据
今天教大家如何爬取新浪网新闻数据,通过词云可视化展示新闻关键词,快速了解最新的新闻热点。这里爬取了**2500**条新闻数据进行演示。

PS:这里采集的主要是国内最新新闻数据。先来看一下数据:

# 1、网页分析
在开始采集之前先说一下新闻数据来源(新浪网)
```
https://news.sina.com.cn/china/
```

### 下一页分析
我们想要采集多条数据,因此需要找到下一页的规律

点击第二页的时候,发现网页链接没有变化,这里数据是通过异步加载过来,因此查看network,找到了目标异步链接:
```
https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8&callback=feedCardJsonpCallback&_=1619440444354
```
但发现callback=feedCardJsonpCallback&_=1619440444354,可以去掉,因此最终链接如下:
```
https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=2&encode=utf-8
```
参数page是页数,经过测试page范围在1~125,到126的时候就请求到的是空数据。每一页一共有20条,因此一共是**2500**条新闻数据。
### json数据结构


这里咱们学院获取三个字段(标题title、原标题intro、关键词keywords)
# 2、采集数据
### 采集第一页
分析好之后,下面开始使用python编程采集数据。
```
url="https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"
```

这是第一页的数据,已经可以成功采集,只需要改变page值就可以采集下一页数据。接着开始把采集的数据存入到excel中。
### 保存数据
这里使用openxl库去将数据保存到excel中,先定义表头
```
outwb = openpyxl.Workbook()
```
接着写入到excel中
```
count = 2
```

# 3、词云可视化
这里主要绘制三个词云可视化(用标题、原标题、关键词分布作为数据去画图)。
标题是原标题的精简版,关键词是这篇文章的核心关键词,通过绘制这个三个词云图,然后进行对比分析。
读取数据
```
datafile = u'新闻数据-李运辰.xls'
```
### 标题词云可视化
```
###标题词云图
```

### 原标题词云可视化
在画词云图之前,先对数据进行处理一下(比如“原标题:”去掉)

```
###原标题词云图
```

### 关键词词云可视化
```
###关键词词云图
```

**分析:**
三个词云图的时事热点都差不多,核心点在于“新冠肺炎”、“病例”、“北京”,“与外交国家等情况”。具体就不过多的说,通过词云图可以一目了然的了解到当前国内的核心热点关键词。
# 4、小结
为了大家方便学习,辰哥把本文的**完整源码**上传,需要的通过同名公众回复:**新闻**
本文讲解了如何去采集新浪网新闻数据并绘制词云图展示分析。
### 采集第一页
分析好之后,下面开始使用python编程采集数据。
```
url="https://feed.sina.com.cn/api/roll/get?pageid=121&lid=1356&num=20&versionNumber=1.2.4&page=1&encode=utf-8"
```

这是第一页的数据,已经可以成功采集,只需要改变page值就可以采集下一页数据。接着开始把采集的数据存入到excel中。
### 保存数据
这里使用openxl库去将数据保存到excel中,先定义表头
```
outwb = openpyxl.Workbook()
```
接着写入到excel中
```
count = 2
```


# 3、词云可视化
这里主要绘制三个词云可视化(用标题、原标题、关键词分布作为数据去画图)。
标题是原标题的精简版,关键词是这篇文章的核心关键词,通过绘制这个三个词云图,然后进行对比分析。
读取数据
```
datafile = u'新闻数据-李运辰.xls'
```
### 标题词云可视化
```
###标题词云图
```

### 原标题词云可视化
在画词云图之前,先对数据进行处理一下(比如“原标题:”去掉)

```
###原标题词云图
```

### 关键词词云可视化
```
###关键词词云图
```

**分析:**
三个词云图的时事热点都差不多,核心点在于“新冠肺炎”、“病例”、“北京”,“与外交国家等情况”。具体就不过多的说,通过词云图可以一目了然的了解到当前国内的核心热点关键词。
# 4、小结
为了大家方便学习,辰哥把本文的**完整源码**上传,需要的通过同名公众回复:**新闻**
本文讲解了如何去采集新浪网新闻数据并绘制词云图展示分析。