MaxCompute(原名ODPS),是阿里巴巴自主研发的海量数据处理平台。 主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。支持PB级别数据分析,常用场景如下:大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。
我们接入MaxCompute主要做两个工作,一是网站的日志分析,二是用户特征和兴趣挖掘。其中网站日志分析项目组内(就是高德开放平台)已经玩的比较溜了,“用户特征和兴趣挖掘”还在探索中。
无论是做数据分析还是数据挖掘,都离不开数据。而MaxCompute不负责收集数据,他只负责处理数据,就好比你有台酸奶机但是没牛奶(MaxCompute比作酸奶机,数据比作牛奶)。所以先把海量的日志数据收集起来是第一步要做的工作。
MaxCompute中的元数据存储在阿里云计算的另一个开放服务Table Store(表格存储服务)中,元数据内容主要包括用户空间元数据、Table/Partition Schema、ACL、Job元数据、安全体系等。
概念清晰了,我们就可以开始动手,下面说说如何将海量的日志收集起来。
一. 数据收集
数据来源我们并不关心,可以是来自MySQL,也可以是文本文件。不过我们的业务场景主要是生产大量的log(文本文件)。比如Nginx请求日志、PHP,Java,Node的服务日志、自建的埋点日志等。
如果你的数据不是文本文件,可以参考这篇文章将数据导入MaxCompute的方法汇总
首先我们要将这些日志收集起来,这里我们使用Fluentd服务(类似的服务还有kafka、LogHub、DataX等,都大同小异,这里我用Fluentd作描述只是方便),通过Fluentd我们轻松的创建任务去按时读取各台服务器上的日志文件。简单点说就是你只需要配置服务器上日志的路径,Fluentd就帮你把日志存储到MaxCompute的Table Store中,然后你就能愉快的通过MaxCompute分析数据了。
使用Fluentd去管理数据收集方式确实能帮我们节省大量人力,而且方式相当便捷,分分钟就能上线泡咖啡!但Fluentd带来便利的同时就需要我们遵守它的规则。比如创建的Table Store表(这样说好别扭,还是叫MaxCompute表吧),必须按照Fluentd定义的字段写,默认四个字段如下
- content 日志内容
- ds 天,Fluentd自动生成
- hh 小时,Fluentd自动生成
- mm 分钟,Fluentd自动生成
PS:如果个人使用Fluentd是可以自定义字段的,不需要像我们一样。我们团队之所以规范字段信息,主要是为了之后的扩展和统一管理(上百个项目)。当然我也建议大家像我们一样规范字段,这样做的好处是之后你能基于Fluentd做平台。
如上可以看到真正能控制的字段只有content,其他字段Fluentd都帮你自动生成。所以在你要做数据分析时就需要用到无数的LIKE,这样不但会导致查询速度慢,最主要和最痛苦的是稍微复杂点的数据分析都无法实现,用LIKE去模仿等于、不等于、包含、不包含难度太高。你好不容易(其实并没有很不容易)把平台搭建好,并说这个服务多牛。一个月后PM要你产出一个报表你发现没办法,PM会觉得你做的啥玩意儿…
这个时候我们可以在埋点时对数据格式做下处理,用些小技巧。比如用各种符号做分隔符,定义一套log格式标准,总归有很多总办法解决问题。但是马总不是说过嘛,解决问题的最好办法就是不给他发生的机会……所以看下文
二. 自建MaxCompute数据源
MaxCompute本身提供了Fluentd的所有功能接口,不过调用接口虽然简单,配置环境却很复杂。如果业务需要对数据做深入的分析和挖掘,就不得不自己配置环境。当然,这也是MaxCompute强大的体现(一般使用成本高的都让人觉得很强大)……
-
首先,我们需要创建Table,这和MySQL基本一样
create table if not exists sale_detail( shop_name string, customer_id string, total_price double) partitioned by (sale_date string,region string); //设置分区分区一定要考虑到,因为MaxCompute的查询最多只能显示5000条数据,limit不支持offect,所以数据量一大就无法通过开发套件(Data IDE)做在线查询。导出数据到本地也需要使用分区字段,分区越大一次请求能导出的数据就越多,合理的设置分区非常重要。
- 通过MaxCompute DataHub Service(DHS) 通常称为Datahub服务,去上传数据。
Datahub服务提供了SDK,不过是Java的,通过SDK可以实现实时上传功能。因为Datahub服务接口不用创建MaxCompute任务(Task),所以速度非常快。可以向较高的QPS(Query Per Second)和较大的吞吐量的服务提供数据存储支持。Datahub上的数据只会被存储7天,之后会被删除,被删除之前会保存到MaxCompute的表中。也可通过异步的方式,调用接口同步Datahub中的数据到MaxCompute的表中。
如果服务本身就使用Java可以直接使用SDK,非Java服务就需要权衡成本。应该还有类似Fluentd的平台,可以到 阿里云MaxCompute工具查找。
三. 流程介绍
在实际项目中使用MaxCompute有4种通用的方案,这里贴出流程图供大家参考;
-
最简单也是最通用的方法,使用Fluentd上传数据,适用于简单的数据存储。如果只是用来收集日志,出问题时容易排查问题可以选择这种方案;流程图如下:
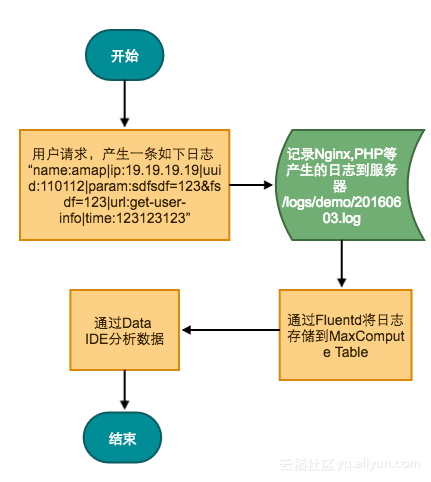 -
比较进阶的方法,使用PyODPS上传数据,适用于较为复杂的数据存储。比如我们需要对收集的日志做转换,例如需要将IP地址转换成城市等;流程图如下:
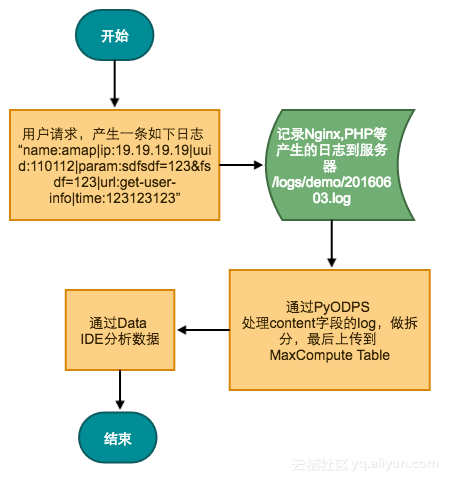 -
比较复杂,易于扩展的方法,需要使用Fluentd和PyODPS上传数据,适用于需要对数据做大量分析的场景。例如多个部门需要的数据埋点也不一样,分析的方法和想得到的报表也不一样等;流程图如下:
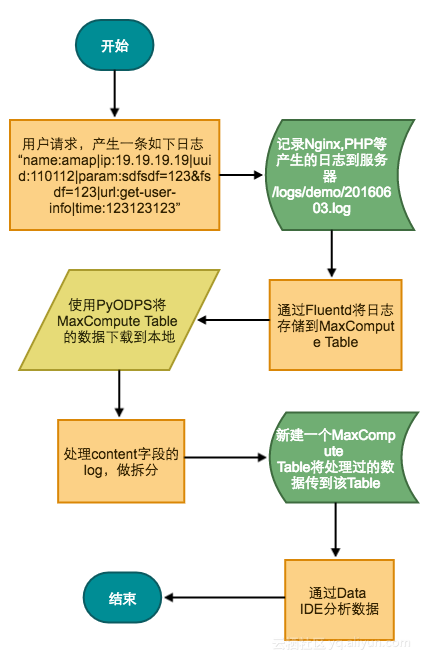 -
最实时的方法,使用Datahub上传数据,适用于需要实时同步数据的业务场景。例如游戏日志处理,电商充值、购物等要求低延的场景;流程图如下:
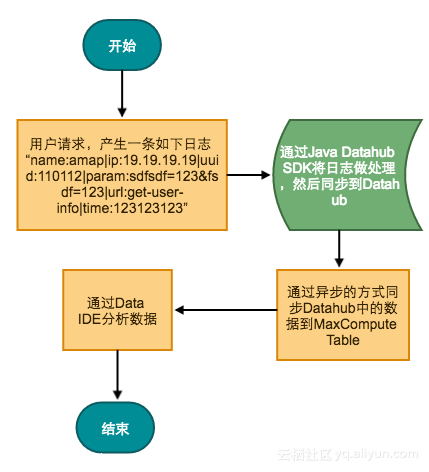
四. 总结
直接在生产环境上调用DHS对我们的PHP环境来说成本太高,所以暂时使用的是Fluentd收集日志数据,然后通过PyODPS将数据下载到本地,处理后再传到MaxCompute Table中。我们的业务场景比较麻烦所以流程显得略复杂,如果你不需要做复杂的数据分析,建议直接使用Fluentd上传数据就行。
五. 最后
最后贴出核心代码,供参考,语言使用Python。
-
封装MaxCompute的连接,这样方便我们随时随地使用MaxCompute的强大功能,只需要在代码中调用一句 “odps = OdpsConnect().getIntense()” ;
#/usr/bin/python3 __author__ = 'layne.fyc@gmail.com' #coding=utf-8 from odps import ODPS # 测试地址:endpoint='http://service-corp.odps.aliyun-inc.com/api' # 正式地址:endpoint='http://service.odps.aliyun-inc.com/api' debug = True onlineUrl = 'http://service.odps.aliyun-inc.com/api' localUrl = 'http://service-corp.odps.aliyun-inc.com/api' accessId = '填自己的' accessKey = '填自己的' class OdpsConnect: model = object def __init__(self): self.model = ODPS(accessId,accessKey,project='项目名', endpoint=(localUrl if debug else onlineUrl)) def getIntense(self): return self.model def exe(self,sql): return self.model.execute_sql(sql) -
创建MaxCompute Table用来存储我们的海量日志,上万亿条数据都不在话下。
from OdpsConnect import OdpsConnect from odps.models import Schema, Column, Partition odps = OdpsConnect().getIntense() odps.delete_table('test_amap_analys', if_exists=True) #表存在时删除 #各种项 columns = [ Column(name='uid', type='bigint', comment='user id'), Column(name='ctime', type='bigint', comment='time stamp'), Column(name='url', type='string', comment='url'), Column(name='param', type='string', comment='param'), Column(name='ip', type='string', comment='ip'), Column(name='city', type='string', comment='city') ] #分区信息 partitions = [ Partition(name='dt', type='bigint', comment='the partition day') ] schema = Schema(columns=columns, partitions=partitions) table = odps.create_table('test_amap_analys', schema,if_not_exists=True)有几点需要特别注意:
- MaxCompute Table只支持添加数据,不支持删除与修改数据。如果要删除脏数据只能先备份整张表到B,再删除这张表A,再新建表A,最后将表B的备份信息处理后重新导入表A;所以,导入数据一定要慎重。
- 分区信息可以创建很多个,但是在导入、导出、某些特殊查询时都要全量带上。比如你的分区字段为“a,b,c,d”,最后你在导出数据时必须指定"a,b,c,d"的内容,只指定‘a,b’或者‘a.c’都是不行的。所以设置分区字段也要慎重,尽量字段设置少点,这里建议通过数据量来设置,建议每个分区存储2W条左右的数据。
-
通过Tunnel上传数据到MaxCompute;
描述:我们通过程序在服务器上埋点了大量日志文件,文件名为“log/20160605.log”每天通过日期定时生成。每条埋点日志的格式为:
“name:amap|ip:19.19.19.19|uuid:110112|param:sdfsdf=123&fsdf=123|url:get-user-info|time:123123123”
使用 ‘|’和‘:’号分隔,现在我们需要将所有日志数据存储到我们上一步创建的“test_amap_analys” 表中。
#/usr/bin/python3 __author__ = 'layne.xfl@alibaba-inc.com' #coding=utf-8 import datetime import urllib.parse #自己封装的IP库 import db.IP from OdpsConnect import OdpsConnect from odps.models import Schema, Column, Partition from odps.tunnel import TableTunnel odps = OdpsConnect().getIntense() t = odps.get_table('test_amap_analys') records = [] tunnel = TableTunnel(odps) #日志文件名格式为 log/20160605.log #这里默认上传前5天数据 sz = 5 while sz > 0 : #get Yestoday last_time = (datetime.datetime.now() + datetime.timedelta(days=-sz)).strftime('%Y%m%d') # 分区不存在的时候需要创建,不然会报错 t.create_partition('dt='+last_time, if_not_exists=True) #创建连接会话 upload_session = tunnel.create_upload_session(t.name, partition_spec='dt='+last_time) #通过日期规则构造的文件名 file = 'log/%s.log' % last_time with upload_session.open_record_writer(0) as writer: for line in open(file,'r',encoding='utf8'): arr = {} #我们的日志使用 ‘|’和‘:’号分隔, #例如:‘name:amap|ip:19.19.19.19|uuid:110112|param:sdfsdf=123&fsdf=123|url:get-user-info|time:123123123’ for tm in raw.split('|'): pstm = tm.split(':') if(len(pstm)==2): arr[pstm[0]] = pstm[1] #nginx中的ip参数可能被伪造,我们需要做过滤 ip = arr.get('ip','') if(len(ip)>15): iparr = ip.split(',') ip = iparr[-1].strip(" ") city = '' if ip != '': #通过ip获取城市信息 city = db.IP.find(ip) writer.write(t.new_record( [ arr.get('uid',0), arr.get('time',0), arr.get('url',''), urllib.parse.unquote(arr.get('param','')).replace("\\","*").replace('"',"*"), #做URL_DECODE ip, city, last_time ])) upload_session.commit([0]) sz = sz - 1;有几点需要特别注意:
- 使用MaxCompute一定要记住,数据为重,分区先行。存储数据,下载数据都要先设置好分区再操作数据。
- Nginx中拿到的IP参数能被伪造,不能直接使用,需要了解的话可看这篇文章 HTTP_X_FORWARDED_FOR伪造
有帮助的URL列表(不定期更新):